¿Cuántas veces te llega una pregunta de un cliente y piensas “pero si la respuesta está ya en la web”?. Seguro que muchas. Pero, ¿hay alguna manera de responder automáticamente a cualquier pregunta que te hagan? Gracias a los avances en IA, y en particular a Haystack, la respuesta es que sí.
Ya sabemos que los bots son una herramienta muy útil para responder rápidamente a nuestros usuarios. Pero un bot sólo es capaz de responder a una lista de preguntas predefinidas para las que ha sido entrenado. ¿Como conseguimos que sea capaz de buscar en el texto de las páginas de la web para responder también a aquellas para las que no ha sido entrenado?.
Aquí es donde Haystack y los modelos preentrenados de lenguaje natural entran en escena. Hace ya tiempo que tenemos modelos de QA (question answering) capaces de responder a preguntas sobre un párrafo de texto. Pero ahí está el problema, que no sirven para textos largos. Se pierden. Para que estos modelos funcionan tenemos primero que ser capaces de identificar los párrafos donde es más probable que esté la respuesta. Lo que, en webs grandes, viene a ser buscar la aguja en el pajar.
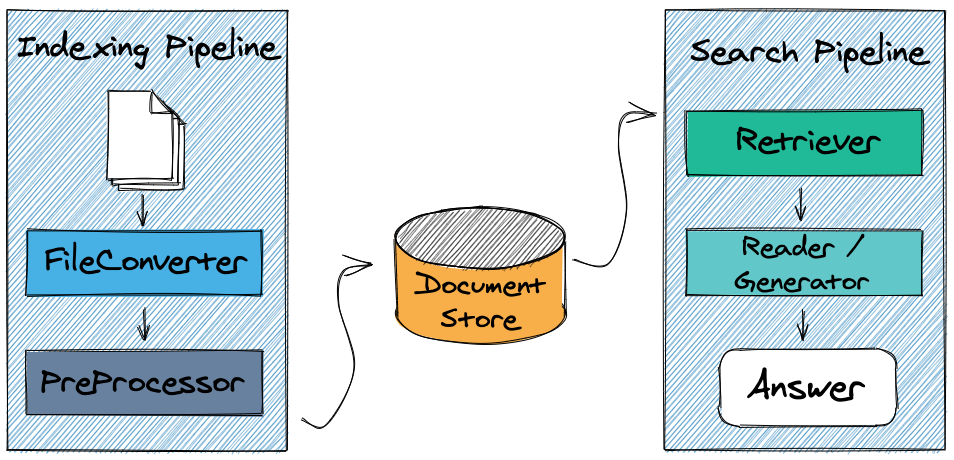
Haystack es un framework de código abierto que integra herramientas para estas dos tareas:
- Seleccionar documentos susceptibles de contener la respuesta a una pregunta utilizando (entre otras opciones) ElasticSearch para indexar y buscar en los documentos (páginas, posts o cualquier otra fuente de datos) de los que dispongamos
- Buscar la respuesta en cada documento seleccionado usando un modelo de QA a elegir
- Devolver las respuestas, su justificación (es decir, de donde viene, el porqué el modelo ha considerado que ésa era la respuesta y la confianza que tiene en que sea la respuesta correcta)
Veamos como he usado Haystack para crear un bot que responde a preguntas de análisis y diseño software para mi web modeling-languages.com.
Creación del bot, el “front-end”
Empecemos por la parte más “fácil” creando el bot con Xatkit. El bot tendrá, como siempre, su lista de preguntas predefinidas. Lo que queremos es que cuando el bot entre en el estado de default fallback, en lugar de decir, “lo siento no te entiendo”, pida a Haystack que le busque una solución.
En este ejemplo tengo toda la infraestructura desplegada localmente pero obviamente en un caso “real” puedes fácilmente tener la web en un servidor, el bot en otro y Haystack en un tercero si así lo deseas.
Carga de la información en ElasticSearch
Para poder encontrar la respuesta primero tengo que cargar en ElasticSearch todos los documentos que quiero utilizar como fuente de información.
En este ejemplo, los documentos serían los posts publicados en la web. Asumiendo que tengamos acceso a la base de datos de WordPress podemos hacer algo como lo siguiente (éste y los siguientes gists son simples adaptaciones de los muchos ejemplos que podéis encontrar en la propia web de Haystack, miradlos para ir viendo también la multitud de opciones de configuración). Fijaros que cortamos os posts en párrafos para evitar que haya documentos demasiado largos para lo que los modelos de QA son capaces de hacer.
Si no tenéis acceso directo a los datos, podéis hacer algo muy parecido pero utilizando la API REST de WordPress.
En el ejemplo uso Flask para poder ejecutar esta carga a demanda.
Búscando la respuesta: Retriever y Reader
El retriever buscará en ElasticSearch los mejores candidatos (por defecto, utilizando el algoritmo BM25). El Reader intentará inferir la respuesta en cada candidato.
Parece complicado pero gracias a las Pipelines que ofrece Haystack, no tiene mayor complicación:
Con la respuesta construimos el objeto que devolvemos al chatbot, que lo imprimirá al usuario.
Pero, ¿y qué tal funciona?
La respuesta es que bastante bien. Creo que mi web no era el ejemplo más fácil. Es grande (más de 1000 posts que se traducen en unos 8000 documentos en ElasticSearch), con muchos solapamientos entre los posts y todavía queda algún post “legacy” en Español lo que confunde aún más. Siempre es buena idea no imprimir solo la respuesta si no añadir también el post de donde se ha sacado para dar más contexto y ayudar a que, en caso de duda, la gente pueda ir a mirarse el post.
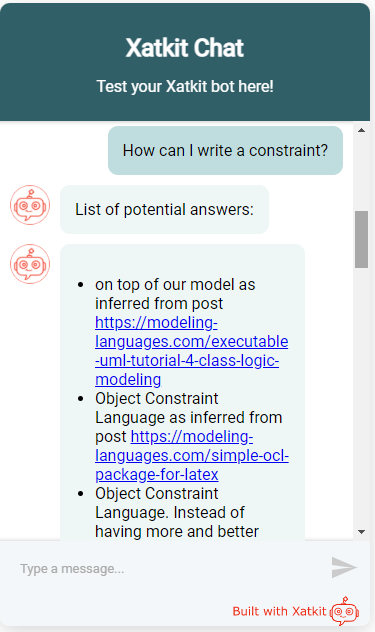
Os pongo dos ejemplos de pregunta / respuesta. En el primero preguntaba que como se podía escribir una restricción en un modelo. La primera respuesta es técnicamente correcta (ciertamente, las restricciones se escriben “sobre” modelos) pero bastante inútil. Las dos siguientes son exactamente lo que esperaba.
La segunda pregunta era más concreta pero con una respuesta más abierta. Fijaros que todas las respuestas las saca del mismo documento (el post donde se explica Temporal EMF). Todas las respuestas son razonables (Temporal EMF es parte del Eclipse Modeling Framework) aunque la tercera es la más útil.
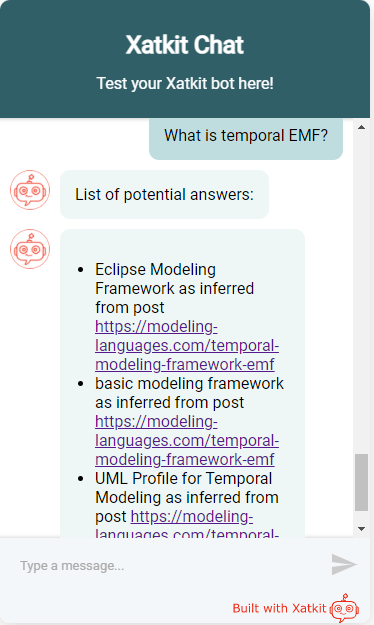
En este ejemplo, seguramente una pipeline “generativa” y no “extractiva” podría haber dado mejores resultados. La diferencia es que en una respuesta generativa, el modelo intenta crear una respuesta a partir de trozos de respuesta que encuentra en el documento mientras que en una extractiva se limita a responder con un trozo de texto literal del párrafo candidato.
A nivel de rendimiento no hubo tampoco problemas. Una vez descargado e inicializado el modelo preentrenado (sólo la primera vez), la respuesta tarda unos segundos en llegar. Pero esto en mi portátil, con más potencia y mejor configuración se puede acelerar lo suficiente como para que el usuario no se queje.
Recordad que si vuestro interés es más el identificar los documentos más relevantes para la pregunta (y no tanto el generar directamente la respuesta), en lugar del Reader, el Ranker será vuestro amigo. Como el Reader, el Ranker se ejecuta después del Retriever pero su objetivo es ordenar los resultados del Retriever usando un análisis más semántico. Como el Reader, utiliza también modelos de lenguaje pero con el objetivo de ordenar los documentos sugeridos.





{kind=link}
Últimos comentarios