
Toda decisión importante debería tomarse en función de los datos disponibles. Esto es tan, o aún más, cierto cuando hablamos de decisiones que afectan a proyectos software. No deberías decidir nada importante sin poder mirar antes los datos que necesites acerca de la evolución del proyecto, sus principales contribuidores (sobre todo si es un proyecto de software libre), las quejas más frecuentes,… La respuesta a estas preguntas casi siempre está escondida en tu repositorio Git (o GitHub, o GitLab, dependiendo de donde tengas alojado el proyecto).
Y aquí es donde empiezan los problemas. No es nada fácil hacer minería de los datos de Git/GitHub. Y si, en lugar de uno, quieres analizar varios proyectos (por ejemplo, para ver como tu proyecto se compara con otros similares), la cosa deviene casi imposible a no ser que le eches muchas horas. Y no es por falta de interés en el tema. Hay muchos investigadores estudiando y analizando proyectos para entender mejor las buenas prácticas de desarrollo, pero sigue siendo un trabajo muy manual.
Hasta la fecha, no he encontrado ninguna herramienta que
- Cubra un buen número de fuentes de datos (obviamente Git y los issue/bug trackers pero también otras fuentes como las listas de distribución o foros que la comunidad use para discutir temas del proyecto)
- Soporte la extracción de datos de un número arbitrario de proyectos bajo demanda. Aún mejor si la herramienta me deja buscar los proyectos que me interesan en función de una serie de criterios de búsqueda (lenguajes, popularidad, tamaño, actividad, dominio, gobernanza …)
- Me deje analizar los datos a mi manera (en lugar de limitarlo a un número predefinido de visualizaciones). Aún mejor si puedo hacer algún tipo de análisis temporal y no sólo la visión estática.
- Y sin tener que perder días preparando los scripts para ejecutar todos los procesos necesarios
Pero aunque no tengo la herramienta perfecta (para mí), hay como mínimo algunas herramientas prometedoras y que pueden ayudarte a definir un proceso ETL para tus datos software. Dependiendo de lo que necesites una puede ser suficiente. O puedes combinarla. Veamos las que me parecen más útiles.
GitHub API
La elección más obvia. GitHub mismo ofrece una API pública para realizar consultas sobre cualquier proyecto. Hay un número máximo de peticiones por hora con lo que usar la API no es una opción si quieres analizar muchos proyectos o proyectos grandes. Pero si lo que quieres es algo más sencillo, como mostrar tu mejor perfil en GitHub, es suficiente. Un aspecto interesante es que puedes subscribirte a ciertos eventos y así ser notificado automáticamente cuando se producen. Esto es, por ejemplo, lo que hacemos en nuestro stargazer bot que nos avisa en Slack cada vez que alguien marca con una estrella nuestros proyectos.
Con esta API puedes acceder a la parte GitHub del proyecto (lo que ves navegando por la página del proyecto) pero tienes muy poca visibilidad sobre “la parte Git” del mismo (ej, no puedes saber fácilmente cuantas líneas de código se modificaron el día anterior).
Microsoft GHCrawler
El GHCrawler es un “crawler” o rastreador que utiliza la API de GitHub para monitorizar un conjunto de proyectos y organizaciones en GitHub. Al utilizar la API de GitHub sigue sometido a las mismas restricciones que acabamos de mencionar pero si puedes conseguir un conjunto de tokens (!para eso están los amigos!), el crawler los va rotando para evitar los límites en la medida de lo posible.
GitHub Archive
GitHub Archive es un proyecto para ir registrando entero el timeline de GitHub. La idea es archivarlo de forma que sea posible acceder a él posteriormente. GH Archive almacena todos los eventos de GitHub en una serie de archivos JSON que puedes descargar y procesar en tu propio ordenador.
GH Archive también está disponible como un conjunto de datos público en Google BigQuery: el dataset se actualiza automáticamente cada hora y permite la ejecución rápida de consultas pseudo-SQL sobre los datos. Aquí podéis ver un ejemplo:
GHTorrent
GHTorrent también monitoriza el timeline de Github . Para cada evento, recupera su contenido y dependencias y lo guarda en una base de datos MongoDB , con la opción también de exportar los datos a MySQL.
Como ves, su objetivo es similar al de GH Archive. La diferencia es que GH Archive busca ser más exhaustivo en los eventos que va registrando mientras que GHTorrent pone más esfuerzo en estructurar un poco más la información antes de guardarla de forma que sea más fácil recuperar no sólo un evento determinado sino también otros eventos relacionados con él. En este artículo puedes ver una comparación más detallada entre GHTorrent y GHArchive.
Kibble
Apache Kibble es una suite de herramientas para recoger, agregar y visualizar la actividad de un proyecto. La arquitectura es similar a Gitana (y de hecho similar a otras que también adoptan este modelo de repositorio central al que se conectan diversos importers/exporters) con un servidor Kibble como punto central y un conjunto de aplicaciones “scanner” especializadas en conectar Kibble con un tipo concreto de recurso (un repo git, una lista de distribución, una instancia de JIRA,… ) y convertir esos datos en objectos unificados que se pueden guardar en el servidor.
Después, con estos datos, puedes crear tu propio dashboard a partir de una serie de widgets y componentes predefinidos para mostrar perspectivas distintas de tus datos (distribución por lenguajes, contribuidores top, evolución del código). Podemos ver Kibble más como una herramienta que te ayuda a crear una web que muestra los datos de tu proyecto como tú quieres.

CHAOSS
CHAOSS es un proyecto de la Linux Foundation focalizado en la definición y cálculo de métricas que ayuden a establecer la salud de la comunidad de un proyecto de software libre. Como parte de esta iniciativa tenemos varias herramientas cuyo objetivo es la minería de datos que servirán de base para el cálculo de las métricas:
- Augur es una aplicación web Flask, una librería Python y servidor REST para definir y calcular de forma rápida métricas de interés a discutir dentro de la comunidad CHAOSS.
- Cregit se focaliza en la generación de vistas que ayudan a visualizar el origen de los cambios en el código.
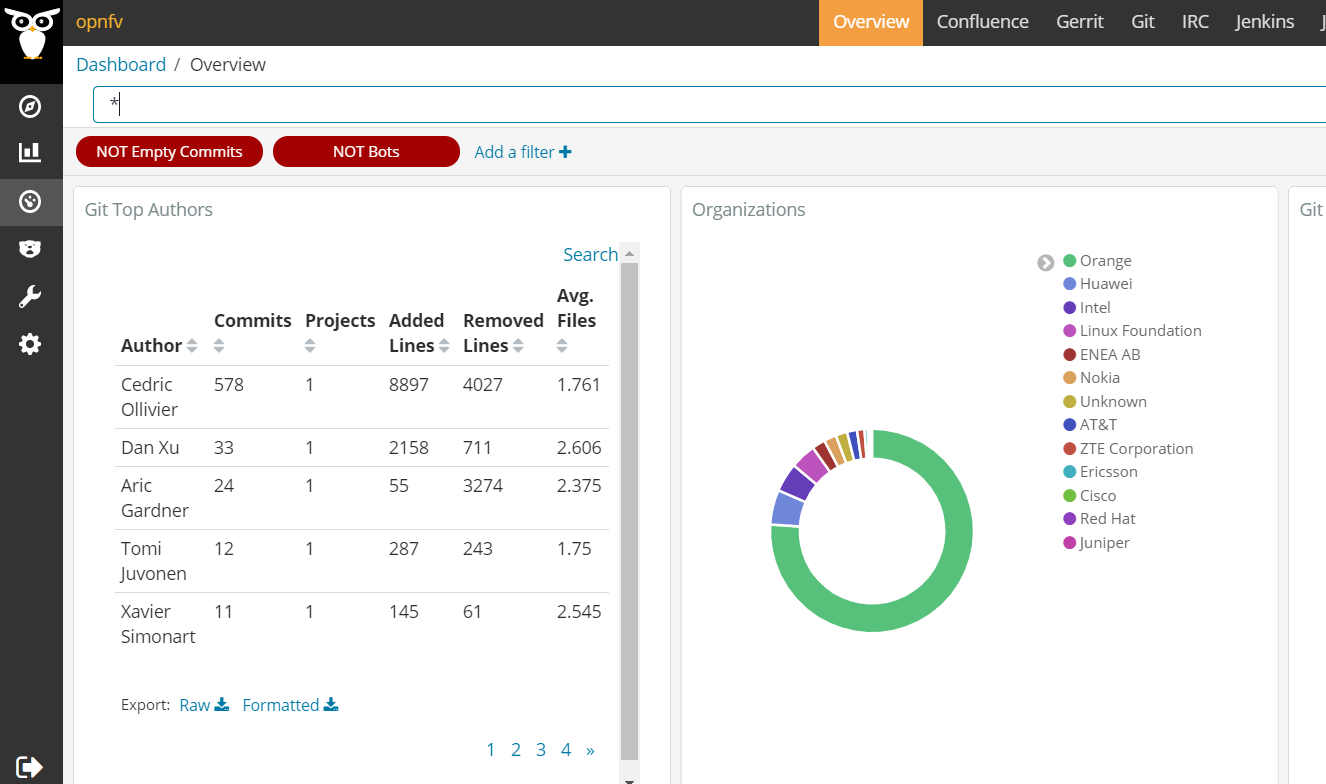
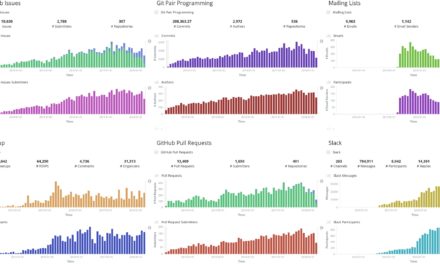
- GrimoireLab (que ya explicamos con más detalle aquí), creada por Bitergia , es de lejos la herramienta más madura y ambiciosa en CHAOSS. El objetivo de GrimoireLab es proporcionar una plataforma open source para :
- Recoger datos de casi cualquier fuente de datos relevante para un proyecto software de una forma automática e incremental
- Enriquecer y limpiar los datos recogidos (gestión de identidades duplicadas, añadir información sobre las afiliaciones de los contribuidores, datos geográficos,…)
- Visualizar los datos, con filtros basados en el proyecto, repositorio, contribuidor individual, dimensión temporal… GrimoireLab utiliza Kibana para crear estas visualizaciones (ver la figura a continuación)
- También gracias a Bitergia, tenemos a Cauldron una solución tipo SaaS (Software as a Service). Es como una versión online de algunos de los componentes de GrimoireLab. ¡Promete mucho! sobretodo gracias a que, al ser SaaS, es muy fácil de usar.
- Prospector tenía un objetivo similar a GrimoireLab pero ha sido ya abandonada.
Gitana
Gitana fue nuestro propio intento de solucionar el problema de minar datos de proyectos construyendo una herramienta genérica y, al mismo tiempo, fácil de usar para el análisis de datos de proyectos. Con Gitana, podías importar los datos de repositorio Git y de su proyecto GitHub asociado en una misma base de datos relacional y una vez integrados automáticamente, analizarlos mediante consultas SQL como harías con cualquier otra base de datos. Gitana venía también con importadores de otras fuentes de datos del proyecto como por ejemplo foros para tener una visión más global del mismo.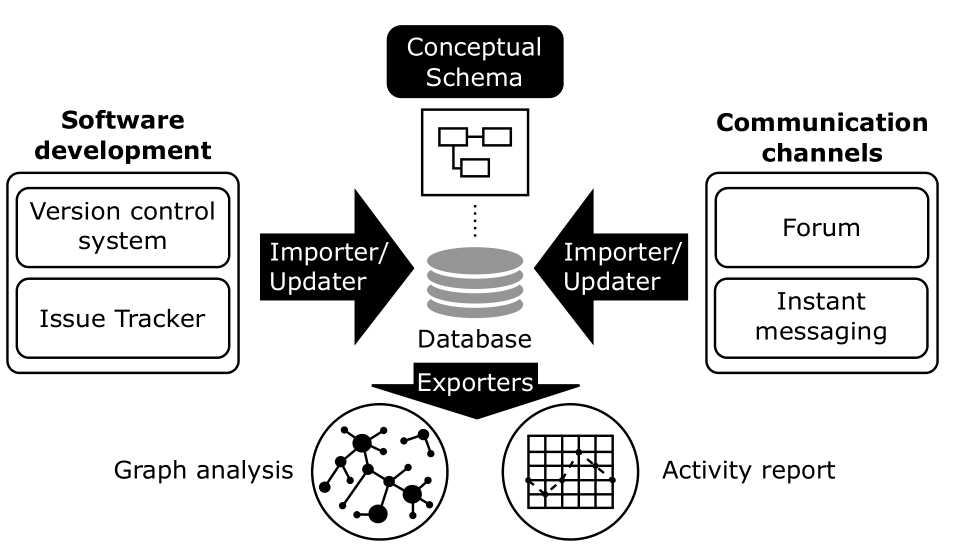
Por desgracia no seguimos con el desarrollo de la herramienta y pasó a formar parte de nuestras herramientas en la categoría archived.
AskGit
AskGit es una herramienta de línea de comandos para ejecutar consultas SQL sobre repositorios Git. Como también pensamos en Gitana, AskGit asume que SQL sigue siendo el lenguaje estrella para la consulta de datos y que, además, es un lenguaje que mucha gente ya conoce con lo que permite a mucha más gente realizar este tipo de análisis.
Ejemplo de una consulta AskGit:
-- how many commits have been authored by user@email.com?
SELECT count(*) FROM commits WHERE author_email = 'user@email.com'
Como se muestra aquí, puedes combinar AskGit con cualquier herramienta de visualización de datos SQL para mostrar gráficamente los resultados de las consultas.
Ten en cuenta, que como su nombre indica, AskGit sólo cubre la parte Git del proyecto y no otros tipos de fuentes de datos.
SourceCred
SourceCred es una herramienta para ayudar a comunidades a medir y recompensar la creación de valor en la comunidad. El objetivo principal de SourceCred no es pues la minería de datos si no el facilitar la implementación de diferentes mecanismos de recompensa para los contribuïdores que aportan valor a la comunidad. Pero, para conseguir este objetivo, el primer paso es ser capaz de recuperar y evaluar los datos de cada contribución. Es por esta faceta que hemos incluido SourceCred en esta lista.
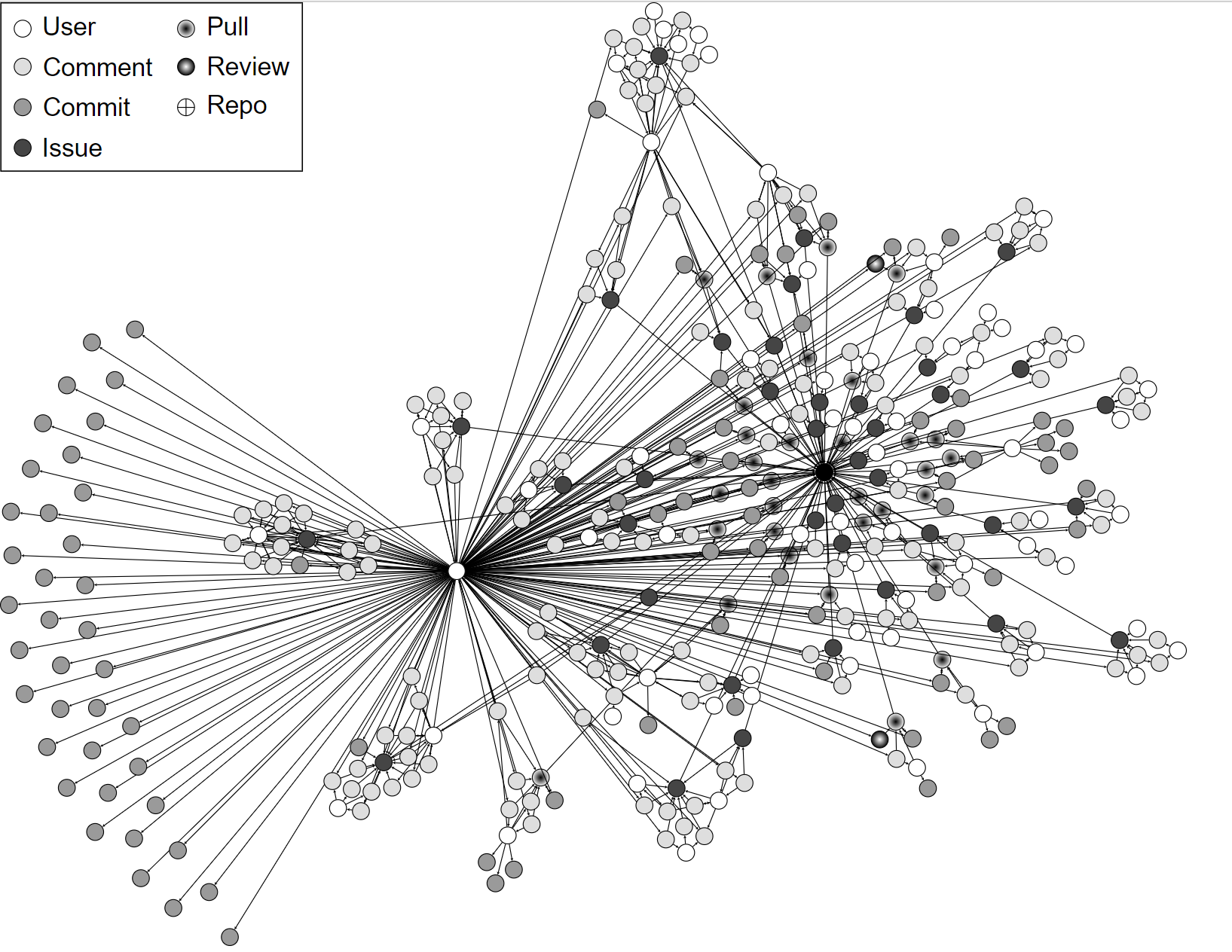
SourceCred es capaz de analizar repositorios GitHub y construir un grafo de colaboración donde los nodos representan los activos del repositorio (ej., usuarios, comentarios, issues, pull requests, etc.) y los vértices representan las relaciones entre ellos (ej., un usuario crea un commit, un comentario se añade a una issue, etc.).
Como ejemplo, éste es el grafo de colaboración para este paquete npm.
Sourced
Sourced se definía a si misma como la “Data Platform for your Development Life Cycle”. A diferencia de las otras, buscaba más ir al análisis muy detallado del código del proyecto y no tanto al análisis de la comunidad alrededor. Gracias a su AST universal, podías hacer preguntas muy concretas sobre el código de forma independiente al lenguaje en el qué ese código estaba escrito.
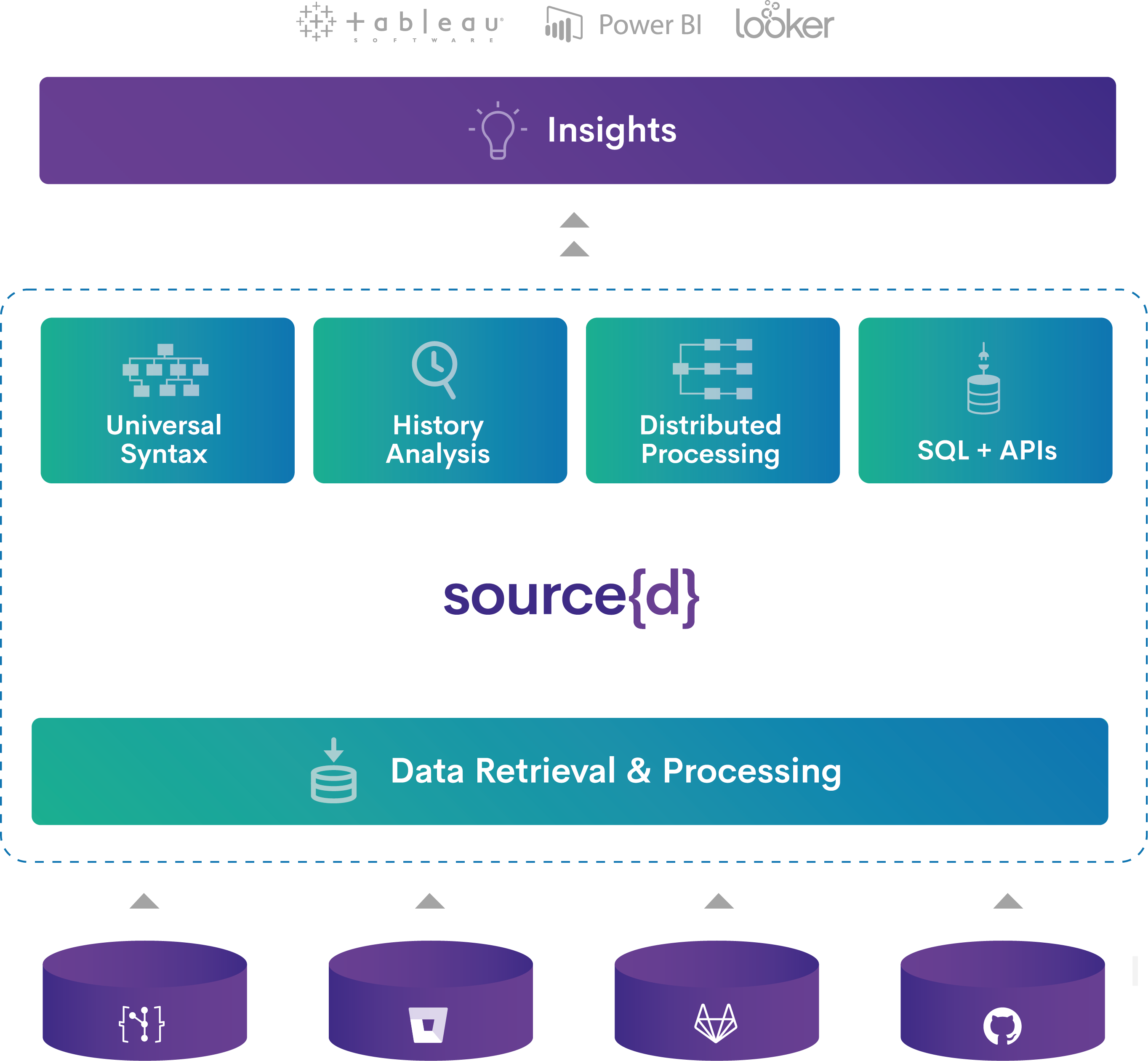
Sourced dejó ya de existir como empresa pero la organización Sourced en GitHub , sigue conteniendo algunos proyectos interesantes. Mis preferidos son go-git (implementación de git en Go), Hercules (para análisis temporales sobre la historia completa de commits de un proyecto) y gitbase ( una interfaz SQL a los repositorios Git ).
Hubble
Hubble visualiza la colaboración en GitHub Enterprise. Como tal, su objetivo con las grandes empresas que buscan entender como sus proyectos internos se organizan y como sus empleados colaboran en ellos.
Hubble Enterprise se divide en dos componentes principales. El updater component es un script de Python que extrae la información de GitHub Enterprise y la guarda en otro repositorio Git una vez al día. El docs component es una aplicación web que visualiza la información recogida en GitHub Pages.
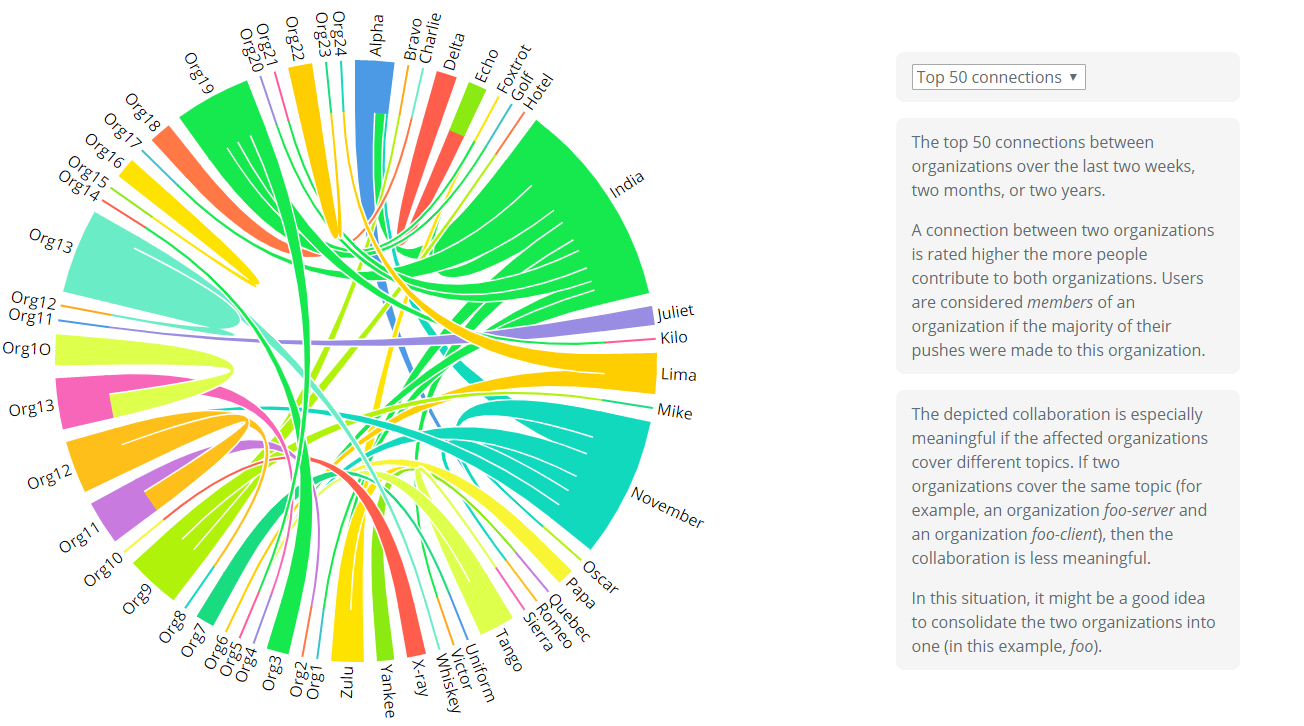
GitCompare
GitCompare extrae las familias de métricas siguientes de un repositorio:
- Activity – Todo tipo de indicadores de actividad (número de commits, forks, tiempo entre commits,…).
- Community – Indicadores sobre la comunidad alrededor del proyecto (stars, watchers, contribuidores…).
- Engagement – Nivel de implicación de la comunidad. Como la anterior pero añadiendo métricas sobre issues and Pull Requests.
- Maintenance – Como de bien mantenido está el proyecto, en función de, por ejemplo, el número de PRs que se cierran.
El objetivo principal de estas métricas es el ayudarte a calcular la “salud” de proyectos competidores para que tengas más datos para elegir con cuál te vas a quedar. Por ejemplo, este gráfico compara algunas de las plataformas de machine learning más populares:

Dependiendo de la importancia que des a cada dimensión escogerás una u otra.
Pero aún hay más
Hay también un par de herramientas comerciales que puedes mirar: Snoot y Waydev. Es curioso también ver que incluso Amazon (OSS Dashboard), Netflix (OSSTracker) y PayPal (Gander) han intentado, en algún momento, crear su propia herramienta de análisis de proyectos software. Todos muertos. Lo mismo que CatWatch.
Como herramientas curiosas también tenemos StackAnalytics (iniciativa que gira alrededor de los datos de la comunidad OpenStack ), Git2Net (paquete Python que facilita la extracción de grafos de co-ediciones a partir de git), AboutCode (conjunto de herramientas para explicitar diferentes aspectos de un proyecto, incluyendo su licencia) y PyDriller (un framework Python que importa y facilita el análisis de los commits, contribuïdores, ficheros modificados, código fuente,… de un repositorio Git).




{kind=link}
También puede utilizar un simple informe HTML sobre el historial de git. Por ejemplo, este https://github.com/bakhirev/assayo