
En este post examinaremos nuestro motor de NLU para chatbots para:
- (obviamente) Utilizarlo para crear vuestros propios bots (conjuntamente con Xatkit ,o cualquier otra plataforma que permita la configuración de un motor NLP externo, para definir los canales de comunicación del bot y su comportamiento)
- Aprender como funcionan las técnicas de procesamiento de lenguaje natural (NLP), concretamente los clasificadores de texto que se usan para “entender” lo que dice el usuario y hacer el matching de ese texto con una de los intents del bot (un intent viene a ser una de las preguntas o peticiones que el bot debería reconocer y responder)
- Desmitificar un poco la complejidad de construir un motor NLP/NLU gracias a reutilizar librerías tan potentes como Tensorflow y animarte a que pruebes de construir el tuyo
¿Listo para empezar a entrar en el mundo NLP? Os doy primero un poco de contexto del proyecto y luego empezamos con el código.
Contents
¿Qué es un clasificador de intents?
Como hemos dicho, un intent o “intención” es una pregunta o petición del usuario para la cual hemos entrenado al bot. Con lo que el bot debería ser capaz de reconocerla y reaccionar a ella.
Un clasificador de intents (en inglés conocido también como intent classifier, intent recognition, intent matching,…) es pues una función que dada el conjunto de intents del bot y una frase del usuario devuelve la probabilidad de que esa frase esté expresando una intención dada.
Hoy en día, estos clasificadores están normalmente implementados como una red neuronal de tipo multi-class classifier.
¿Necesita realmente el mundo otro motor NLP para chatbots?
Seguramente no. De hecho, en Xatkit proponemos la idea de las plataforams de orquestaci’on de bots justamente para no reinventar la rueda. Vaya, que en la mayoría de los casos vas más que servido con los motores que ya existen (en la nube, vía APIs, como DialogFlow o, locales, como nlp.js). Pero ya hemos dicho al empezar que hay otras razones para crear tu propio motor (para aprender nada mejor que escribir y probar código uno mismo) y siempre hay ese caso especial donde un bot requiere una adaptación específica que no te pueden dar herramientas externas que muchas veces son black-box (al no ser software libre) o requerirían bastantes horas para llegar a entender como funcionan o no permiten fácilmente una configuración diferente a la habitual.
¿Qué hace nuestro motor de NLP diferente?
Pues nuestra idea es tener un motor que sea flexible y, al mismo tiempo, muy pragmático. Veamos un par de ejemplos que nos ayudarán también a entender mejor el código.
Xatkit te lo deja configurar casi todo
Como se procesan los datos, los hiperparámetros de la red, como se comporta el clasificador,… todo puede configurarse.
Xatkit crea a una red neuronal diferente para cada punto de la conversación
Para mí un bot se asemeja a una máquina de estados, donde en cada estado de una conversación entre el bot y el usuario sólo un subconjunto de todos los intents tiene sentido. Creo que es mucho más óptimo tener una red neuronal especializada en ese subconjunto de intents que una sola entrenada a nivel global de la que luego tengamos que filtrar los intents que no tengan sentido.
No siempre una red neuronal es la mejor opción
A veces es matar moscas a cañonazos. Si en un estado concreto el usuario sólo puede, por ejemplo, contestar “Sí” o “No” (pensad incluso que la interfaz del bot puede tener botones en algún caso y no permitir la entrada de texto libre), ¿para qué crear una red neuronal? O sí la frase que entra el usuario no tiene sentido (ejemplo: no son palabras que existan en el diccionario), ¿porqué gastar tiempo de computación intentando predecir que puede ser en lugar de simplemente decir automáticamente que no se corresponde a ningún intent?
Este tipo de decisiones no pueden configurarse en otros motores que siempre aplicarán la solución AI a todo, incluso cuando no sea lo más inteligente 🙂
¡Quiero ver el código!
En el núcleo de nuestro clasificador tenemos un modelo Keras / Tensorflow . Pero antes de usarlo hay que entrenarlo y para entrenarlo le vamos a dar un conjunto de ejemplos para cada intent que deba reconocer. Los ejemplos serán frases típicas que un usuario podría utilizar al expresar ese intent. Por ejemplo, para un intent que tenga que reconocer que el usuario está pidiendo los horarios de apertura, pues tendríamos como sentencias de entranemiento frases como “¿Cuando está abierto?”, ¿a qué hora abrís? ¿Cuál es vuestro horario?, etc. Parte del código estará pues dedicado a procesar estas frases para poder usarlas durante el entrenamiento.
Finalmente, para que sea fácil de integrar en cualquier aplicación, añadiremos también una API REST por encima.
Esto nos da un proyecto Python con la siguiente estructura: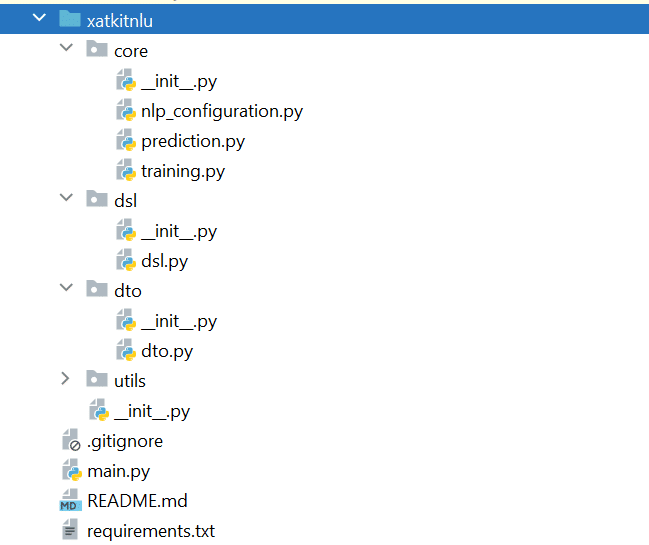
El Main.py contiene la definición de la API, creada con FastAPI. El paquete dsl se encarga de las estructuras de datos para guardar los datos del bot. En el dto encontrarás versiones simplificadas de las clases del dsl para usar de entrada/salida en las llamadas a la API. Finalmente, el paquete core incluye las opciones de configuraciones y el núcleo del proyecto con el código para el entrenamiento y la predicción.
La red neuroanl
El núcleo del motor es un modelo Tensorflow.
Las capas y parámetros son bastante estándar para un classifier. Dos aspectos que vale la pena mencionar:
- El número de clases en la salida dependen del valor de
len(context.intents). Con lo que tenemos tantas clases como posibles intents tenga el bot definido para ese contexto conversacional concreto. - Usamos la función sigmoid en la última capa ya que los intents no son mutuamente exclusivos y queremos ver la probabilidad para cada uno de formaa independiente.
Preparando los datos de entrenamiento
Como hemos visto antes para cada contexto hay un conjunto de intents y para cada intent un conjunto de sentencias de entrenamiento.
Primero creamos los datos etiquetados (pares
Para entenderlo mejor:
- Asignamos un valor numérico a cada intent y lo usamos al poblar la lista
total_labels_training_sentences. - Usamos un tokenizer para crear un índice de las palabras que aparecen en las sentencias con la llamada
fit_on_texts. Este índice se usa para convertir las palabras de las sentencias a números (texts_to_sequences). En este punto, las sentencias de entrenamiento ya están codificadas como secuencias de números que llamamostraining_sequences - El padding garantiza que todas tendrán la misma longitud. La longitud máxima, como todo, es parte de la configuración del motor NLP.
- Finalmente entrenamos el modelo llamando
fit
Predicción del mejor intent para lo que ha escrito el usuario
Una vez el modelo está entrenado, predecir se reduce a una llamada al modelo. Eso sí, antes hay que procesar la frase de entrada igual que hemos hecho antes con las frases de entrenamiento. Fijaos que también hay implementada ya una de las optimizaciones de las que hemos hablado antes: si la frase de entrada está compuesta enteramente de palabras para los que el bot no ha sido entrenado no hace falta molestarnos a llamar al modelo, directamente determinamos que es imposible que sea un match para nada.
Utilizar el motor NLP vía una API REST
El módulo main.py se encarga de exponer una API pública implementada con el framework FastAPI. Como ejemplo, aquí os pongo el endpoint para entrenar el bot. Fijaros que para definir los tipos de los datos de entrada utilizamos Pydantic que facilita el procesamiento de los JSON de entrada y salida. Los tipos son la versión dto de las clases del dsl.
¿Os animáis a jugar con el motor?
¡Perfecto!. Ya podéis ir a https://github.com/xatkit-bot-platform/xatkit-nlu-server, seguir las instrucciones de instalación y ejecutarlo vosotros mismos. Aún mejor si además nos dejáis una estrella en el repo que siempre se agradece. Y si además os animáis a colaborar con el proyecto encantado de hablarlo con vosotros y recibir vuestras contribuciones.




{kind=link}
Últimos comentarios