Con el lanzamiento de nuevos, y aún más potentes, Large Language Models (LLMs, modelos de lenguaje con grandes cantidades de datos) como Copilot y ChatGPT, muchos de nosotros nos preguntábamos si en realidad son buenos no solo para programar, sino también para modelar. Creo que hay pocas dudas de que los LLM han llegado para quedarse y que van a revolucionar la forma en que se desarrolla el software, pero: ¿Hasta qué punto se pueden utilizar los LLM hoy en día para modelar sistemas de software?
Si bien hay muchos artículos dedicados a analizar las posibles ventajas y limitaciones de estos modelos generativos de IA para escribir código, el análisis del estado actual de los LLM en relación con el modelado de software ha recibido poca atención hasta ahora.
En un reciente artículo [1] publicado en acceso abierto en la revista Software and Systems Modeling, hemos investigado las capacidades actuales de ChatGPT para realizar tareas de modelado y ayudar a los modeladores parte de un equipo de diseño software, al mismo tiempo que intentamos identificar sus principales deficiencias.
Resumen: Nuestros hallazgos muestran que, a diferencia de la generación de código, el rendimiento de la versión actual de ChatGPT para el modelado de software es limitado, con diversas deficiencias sintácticas y semánticas, falta de consistencia en las respuestas y problemas de escalabilidad.
Introducción
La mayoría de expertos prevén un gran cambio en la forma en que se desarrolla el software y se espera que hasta la educación en ingeniería de software cambie drásticamente con la llegada de los LLM. Estos problemas son un tema recurrente en muchas universidades y objeto de estudio en una multitud de artículos que exploran las posibles ventajas, limitaciones y fallas de estos modelos para escribir código, así como la forma en que los programadores interactúan con ellos. La mayoría de los estudios parecen estar de acuerdo en que los LLM hacen un excelente trabajo al escribir código: a pesar de algunos errores sintácticos menores, lo que producen es fundamentalmente correcto.
Sin embargo, ¿qué sucede con el modelado de software? ¿Cuál es la situación de los LLM cuando se trata de realizar tareas de modelado o ayudar a los modeladores a llevarlas a cabo? Hace unos meses, junto con mis colegas Javier Cámara, Javier Troya y Antonio Vallecillo, comenzamos a investigar estos problemas, tratando de indagar en el estado actual de los LLM en relación con el modelado conceptual. Nuestra premisa es que los LLM están aquí para quedarse. Por lo tanto, en lugar de ignorarlos o rechazar su uso, sostenemos que sería mejor aceptarlos y utilizarlos de manera efectiva para ayudarnos a realizar tareas de modelado.
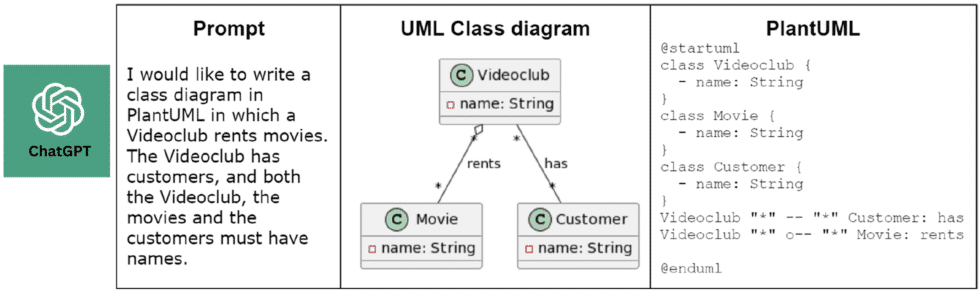
En nuestro artículo [1], nos centramos en cómo construir diagramas de clases UML enriquecidos con restricciones OCL utilizando ChatGPT. Para ello, investigamos varios aspectos, como:
- la corrección de los modelos producidos;
- la mejor manera de pedirle a ChatGPT que construya modelos de software correctos y completos;
- su cobertura de diferentes conceptos y mecanismos de modelado;
- su expresividad y capacidad de traducción entre lenguajes de modelado; y
- su sensibilidad al contexto y a los dominios de problemas a modelar.
Experimentos
Llevamos a cabo un experimento para comprender mejor las capacidades actuales de ChatGPT en relación con tareas de modelado. Definimos dos fases:
- algunas pruebas exploratorias para obtener una comprensión básica de cómo ChatGPT funciona con modelos de software, así como sus principales características y limitaciones; y
- pruebas más sistemáticas que tenían como objetivo caracterizar aún más las capacidades de modelado de ChatGPT.
Todos los detalles de los experimentos, los materiales y ejemplos, y todos nuestros hallazgos se enumeran en nuestro artículo.
En concreto, formulamos ocho preguntas de investigación para las cuales queríamos encontrar una respuesta. Éstas se presentan a continuación.
RQ1.: ¿Genera ChatGPT modelos UML sintácticamente correctos?
Los modelos UML producidos por ChatGPT son generalmente correctos, aunque pueden contener pequeños errores sintácticos, que dependen de la notación utilizada (PlantUML, USE, texto plano, etc.). Por ejemplo, aunque no lo hemos probado exhaustivamente, el nivel de corrección sintáctica de los modelos producidos en PlantUML fue mucho mayor que los generados en USE.
RQ2.: ¿Genera ChatGPT modelos semánticamente correctos, es decir, alineados semánticamente con la intención del usuario?
Este es el punto más débil que observamos durante nuestra interacción con ChatGPT. Algunos estudios sugieren que los LLM son mejores en sintaxis que en producir resultados semánticamente correctos, y nuestros hallazgos corroboran este hecho. Esto incluye errores tanto en la semántica del lenguaje como en la semántica del dominio que se está modelando. En muchas ocasiones, observamos que ChatGPT proponía modelos aparentemente aleatorios que no tenían sentido ni desde un punto de vista de modelado ni desde el punto de vista del dominio.
RQ3.: ¿Qué tan sensible es ChatGPT al contexto y al dominio del problema?
Nuestros hallazgos muestran que no solo el dominio del problema influye en los modelos resultantes, sino también la información intercambiada durante los diálogos con ChatGPT. Además, cuanto más “sabe” ChatGPT sobre un dominio (es decir, cuantos más datos sobre un dominio se utilizaron durante el entrenamiento), mejores son los resultados. En efecto, ChatGPT produce sus peores resultados cuando tiene poca o ninguna información sobre el dominio o las entidades que se van a modelar, como sucedió al pedirle que produjera modelos de software de entidades como Snarks o Zumbats, para las cuales no parecía tener ninguna referencia ni anclaje semántico.
RQ4.: ¿Cómo de grandes son los modelos que ChatGPT es capaz de generar o manejar?
Actualmente, ChatGPT tiene limitaciones estrictas en el tamaño de los modelos que puede manejar. Tiene problemas serios con modelos de más de 10-12 clases. Incluso el tiempo y el esfuerzo requeridos para producir modelos más pequeños es significativo.
RQ5.: ¿Qué conceptos y mecanismos de modelado es capaz de utilizar eficazmente ChatGPT?
Analizamos 16 conceptos de modelado. Algunos de ellos tan simples como clases y atributos, y otros más avanzados como restricciones OCL y clases asociativas. Observamos que hay un alto grado de variabilidad en cómo ChatGPT los maneja. ChatGPT puede gestionar razonablemente bien (con algunas excepciones) asociaciones, agregaciones y composiciones, herencia simple y nombres de roles de extremos de asociación. Sin embargo, requiere indicaciones explícitas para utilizar enumeraciones, herencia múltiple y restricciones de integridad. Finalmente, descubrimos que no es capaz de trabajar con clases asociativas.
RQ6.: ¿La variabilidad en los prompts afecta la corrección/calidad de los modelos generados?
Observamos que hay mucha variabilidad cuando ChatGPT genera respuestas para el mismo prompt. Es útil comenzar una nueva conversación desde cero cuando los resultados no fueron buenos, con el fin de encontrar mejores soluciones para el mismo modelo objetivo.
RQ7.: ¿Diferentes estrategias de uso (por ejemplo, encadenado o partición de prompts) producen resultados diferentes?
En primer lugar, el tamaño de los modelos que ChatGPT es capaz de manejar en una sola consulta hace que la tarea de modelado se convierta en un proceso iterativo en el que el usuario comienza con un modelo pequeño y agrega progresivamente detalles. La variabilidad y aleatoriedad de las respuestas de ChatGPT o cuando los resultados dentro de una conversación comienzan a divergir a menudo obligan al modelador a repetir conversaciones para intentar obtener mejores modelos.
RQ8.: ¿Qué tan sensible es ChatGPT a la notación UML utilizada para representar los modelos de salida?
ChatGPT es capaz de representar modelos con varias notaciones, aunque en general comete menos errores sintácticos con PlantUML. También es mucho mejor con OCL que con UML. Finalmente, también observamos qué tan preciso era ChatGPT con la traducción de lenguaje de modelado cruzado, y nos dimos cuenta de que esta tarea funciona mejor dentro de la misma conversación, pero no entre conversaciones diferentes.
Discusión y Conclusiones
A partir de nuestro estudio, concluimos que ChatGPT aún no es una herramienta fiable para realizar tareas de modelado. ¿Significa eso que deberíamos descartarlo, o al menos esperar a ver cómo evoluciona antes de tomar alguna acción? Nuestra posición es que, al contrario, deberíamos comenzar a trabajar ahora para fortalecer las habilidades de modelado de ChatGPT y otros LLMs por venir (incluyendo también sus capacidades con respecto a la comprensión de otros lenguajes más allá de UML por parte de los LLMs), y construir un futuro en el que estos asistentes estén destinados a desempeñar un papel destacado en el modelado.
En nuestra opinión, ChatGPT o cualquier otro LLM puede ser de ayuda invaluable en muchas áreas del desarrollo de software dirigido por modelos, complementando el trabajo actual de los modeladores de software y permitiéndoles enfocarse en tareas en las que realmente aportan valor.
El uso de LLMs tiene el potencial de revolucionar la ingeniería y educación en el modelado de software, haciéndolo más accesible, personalizado y eficiente. Para llegar a ese punto, primero necesitaremos mejorar la consistencia y fiabilidad actuales de los modelos producidos por LLMs como ChatGPT. Segundo, necesitaremos cambiar la forma en que actualmente desarrollamos modelos de software y enseñamos el modelado.
¡Te animamos a leer nuestro artículo para obtener más detalles y contactarnos si deseas discutir!
Referencias
[1] Javier Cámara, Javier Troya, Lola Burgueño, Antonio Vallecillo. On the assessment of generative AI in modeling tasks: an experience report with ChatGPT and UML. Softw Syst Model (2023). DOI: 10.1007/s10270-023-01105-5






{kind=link}
Últimos comentarios