
Seguimos enamorados de toda la potencia que ofrecen los Modelos de Lenguaje de Gran Tamaño (Large Language Models – LLMs). Aún más con el reciente soporte a la generación de texto / scripts a partir de imágenes disponible en algunos LLMs como ChatGPT4 de OpenAI. Gracias a esta funcionalidad, hemos visto la aparición de algunas herramientas de diseño que permiten la generación de código HTML, CSS y JS a partir de capturas de pantalla de páginas web o simplemente maquetas con descripciones textuales adicionales. Un ejemplo que utiliza ChatGPT4 sería Make-real.
Viendo esto, me pregunté: ¿Qué tal si utilizamos las capacidades de comprensión de imágenes de los LLMs para generar diagramas de clases UML a partir de fotos de modelos o incluso bocetos de modelos hechos a mano?”
¿Por qué deberías seguir leyendo?
La adopción de herramientas de modelado es un tema de constante debate. Y la usabilidad de dichas herramientas es una queja común. Creo que todos podemos estar de acuerdo en que la manera más rápida de crear un diagrama de clases UML es dibujándolo a mano. No solo en un papel, sino también en una pizarra, lo que además permite la colaboración de un equipo de diseño.
Imagina una reunión de equipo para discutir el diseño de una aplicación, donde las ideas se recogen colaborativamente en un diagrama de clases UML en una pizarra. Si una vez dibujado y acabada la reunión hay que, a mano, “pasar el dibujo a limpio”, por ejemplo, para fines de documentación, es una pérdida de tiempo enorme. Además, se podría desear, no sólo un diagrama bonito sino también en un formato que se pueda importar en una herramienta de modelado real para usar el diagrama de clases UML en un proceso de generación de código. ¿No sería genial poder simplemente tomar una foto de la pizarra y tener inmediatamente su transformación en un diagrama UML “real”?
Esto también es necesario como parte de proyectos de migración de sistemas heredados done, lo más probable, es que no encontremos los modelos de especificación y diseño del sistema, pero aún así podríamos encontrar algunos dibujos como parte de la documentación del sistema. Con una herramienta de imagen a UML, al menos podríamos crear algunos primeros modelos basados en esos.
¿Y no se ha intentado ya pasar de imagen a modelos UML antes?
Sí. No somos los primeros en intentar llevarlo a cabo. Pero los intentos anteriores se basaban en técnicas estándar de OCR con resultados limitados (por ejemplo, no funcionaban con modelos dibujados a mano). Un ejemplo sería el trabajo Img2UML: Un sistema para extraer modelos UML de imágenes, destinado a extraer los modelos de clases UML de imágenes y producir archivos XMI del modelo UML. Desafortunadamente, no hemos podido acceder y probar la herramienta. Otros trabajos solo se centraron en clasificar los contenidos de la imagen en diferentes tipos de diagramas UML, por ejemplo, Reconociendo automáticamente los elementos semánticos de imágenes de diagramas de clases UML.
Finalmente, los intentos de utilizar LLMs para crear diagramas de clases UML se describen en Sobre la evaluación de la IA generativa en tareas de modelado: experiencia con ChatGPT y UML y Modelado Conceptual y Modelos de Lenguaje de Gran Tamaño: Impresiones tras los Primeros Experimentos con ChatGPT. Aunque proporcionan resultados positivos respecto a la capacidad de ChatGPT para producir diagramas PlantUML, los modelos solo se crean a partir de indicaciones textuales.
Nuestro Experimento
Dado que nadie parece haber explorado si las nuevas capacidades de visión en LLMs recientes podrían ser la solución, nos propusimos responder a esta pregunta nosotros mismos.
Configuración
Como los LLMs se centran en generar texto, intenté generar a partir de una imagen el diagrama de clases UML equivalente en sintaxis PlantUML. PlantUML es una herramienta de modelado textual que permite, por ejemplo, la creación de diagramas de clases UML utilizando una sintaxis simple e intuitiva. Es útil para visualizar y comunicar rápidamente la estructura de sistemas de software.
Creé 4 diagramas de clases UML diferentes y para cada diagrama dibujé 2 versiones (una en la pizarra y otra en papel) y una versión modelada con draw.io que capturé en pantalla. En este post, voy a usar la imagen tomada del dibujo en la pizarra para el análisis pero las otras variaciones daban resultados similares.
Cada dibujo lo procesé con Microsoft Copilot, el modelo GPT-4-Vision de OpenAI a través de la API, el modelo gratuito CogVLM y el chatbot Bard de Google. Mostraré a continuación los resultados generados, pero también señalaré el número de errores por generación. Por razones de simplicidad, cuento como error cada elemento que falta o sobra respecto al diagrama original.
El prompt siempre fue el mismo: “¿Puedes convertir este diagrama de clases UML dibujado a mano en el correspondiente diagrama de clases plantuml?“.
Resultados
La primera imagen del experimento y el modelo UML esperado es el siguiente:
| Picture | Expected Outcome |
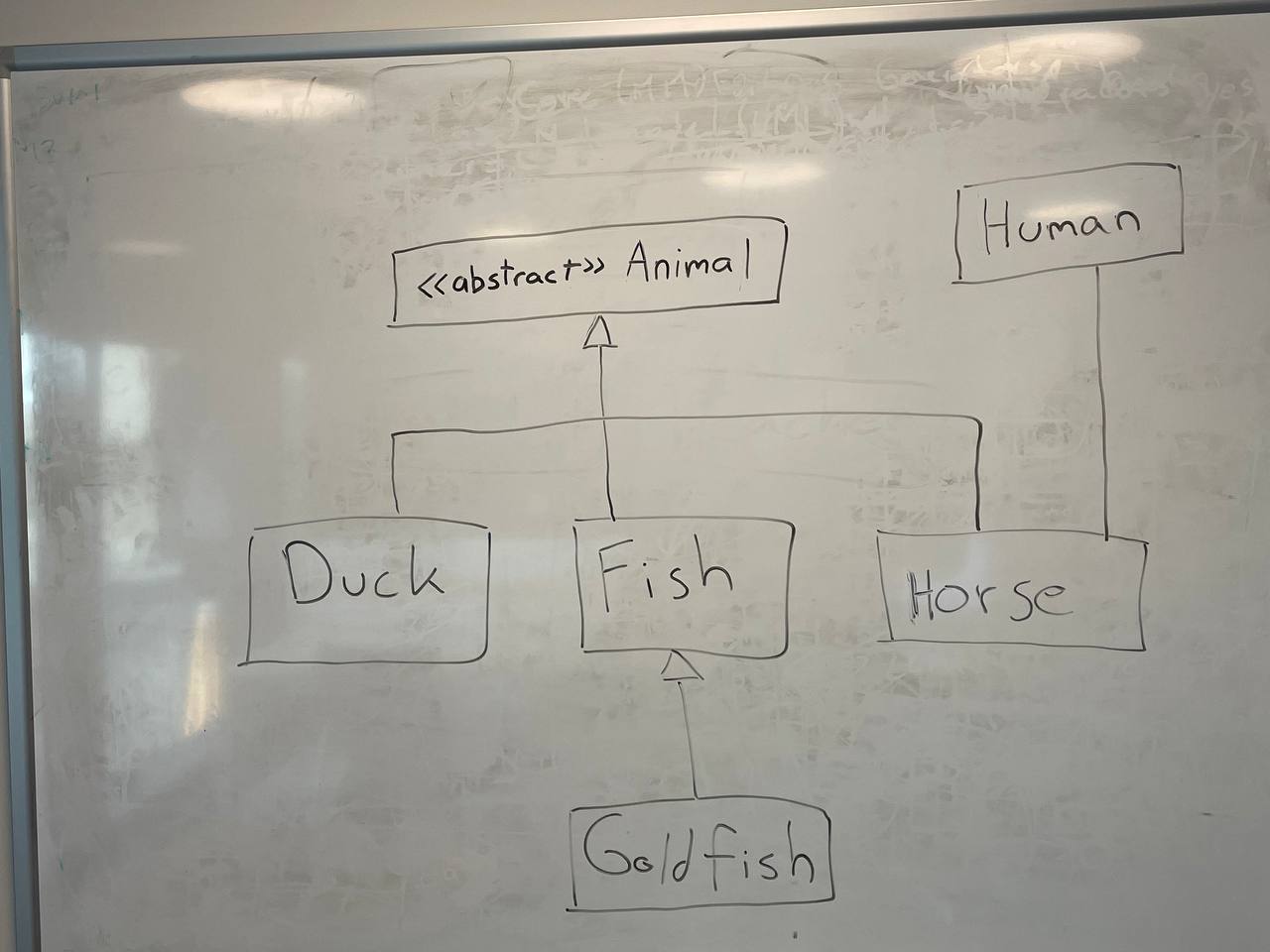 |
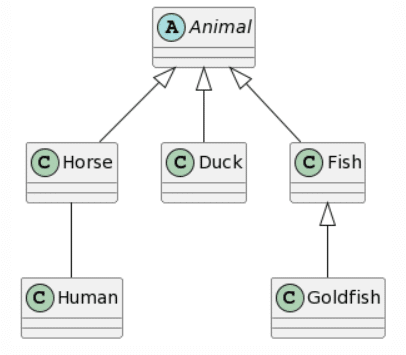 |
Y estos los resultados que conseguí con cada LLM:
| Microsoft Copilot: 3 mistakes |
ChatGPT4: 2 mistakes |
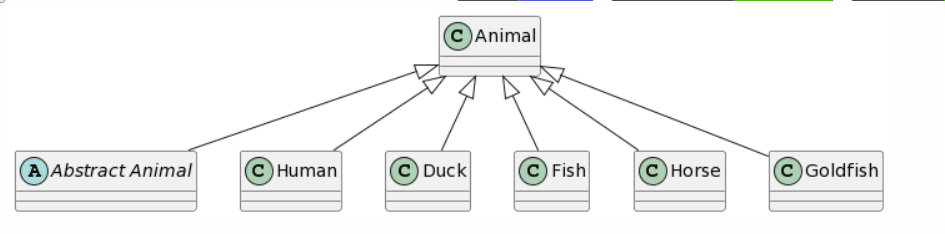 |
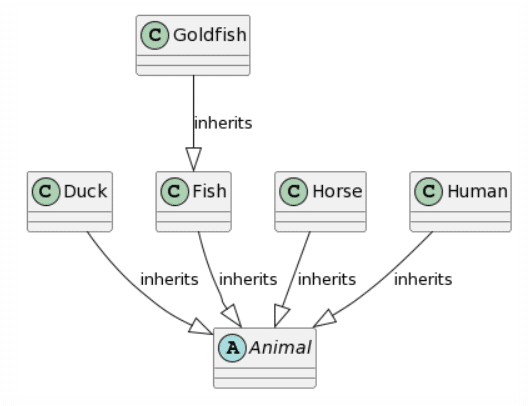 |
| CogVLM: 10 mistakes | Bard: 3 mistakes |
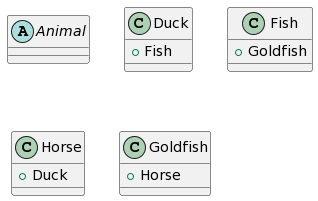 |
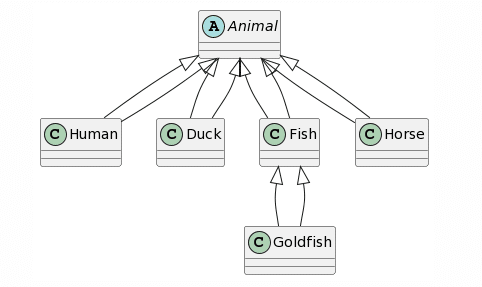 |
A destacar que, para Bard, fueron necesarios 3 intentos hasta obtener un diagrama PlantUML. Los dos primeros intentos dieron como resultado una respuesta que afirmaba que transformar una imagen que contiene un diagrama de clases UML a PlantUML estaba fuera de su alcance. En cuanto a los resultados, ChatGPT4 proporciona la representación más completa, siendo el único problema la falta de una asociación unidireccional entre Caballo y Humano y la adición de una generalización de Animal a Humano. Bard proporciona un resultado similar, la única diferencia es que cada clase hereda dos veces de Animal (lo que consideramos como 1 error). Microsoft Copilot se desvía un poco más al agregar una clase l y hacer que Pez Dorado herede de Animal en lugar de Pez. Finalmente, CogVLM proporciona algunas clases con nombres correctos, pero sin relaciones y con algunos atributos cuestionables que parecen derivados de las otras clases.
En el siguiente experimento quería ir un paso más allá y ampliar nuestro diagrama de clases agregando atributos y métodos:
| Picture | Expected Outcome |
 |
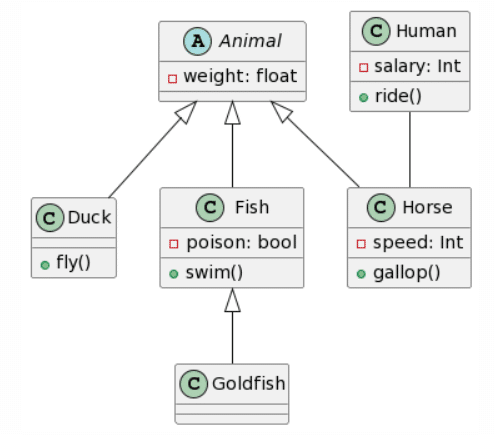 |
Puedes ver como hay algunos elementos inconsistentes, como el cambio de color debido a que el marcador negro ya no funciona y la reflexión de la luz. Creía que esto podría afectar los resultados, sin embargo, en la vida real, aspectos como estos no se pueden evitar con lo que tampoco está mal que se hayan dado en este experimento.
Y aquí está el primer resultado para cada uno de los LLMs:
| Microsoft Copilot: 10 mistakes |
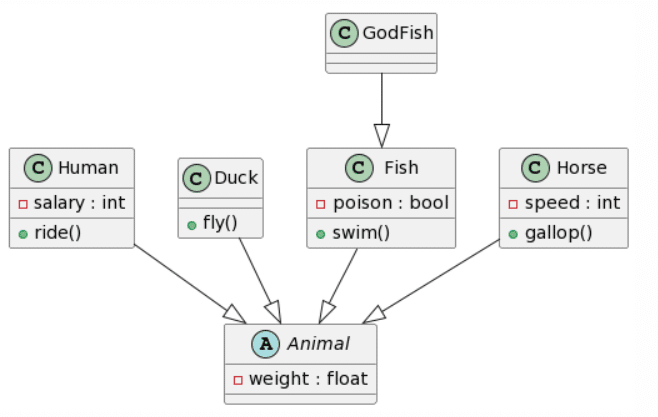
ChatGPT4: 2 mistakes |
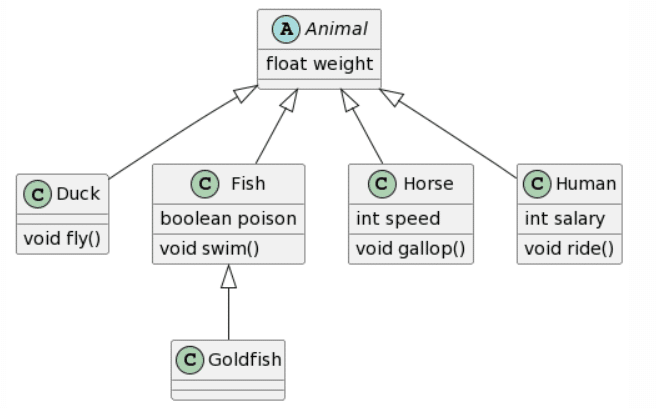 |
 |
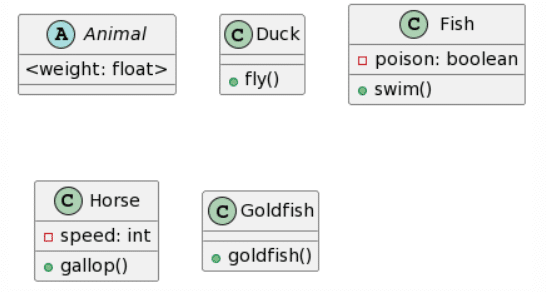
| CogVLM: 9 mistakes | Bard: 5 mistakes |
 |
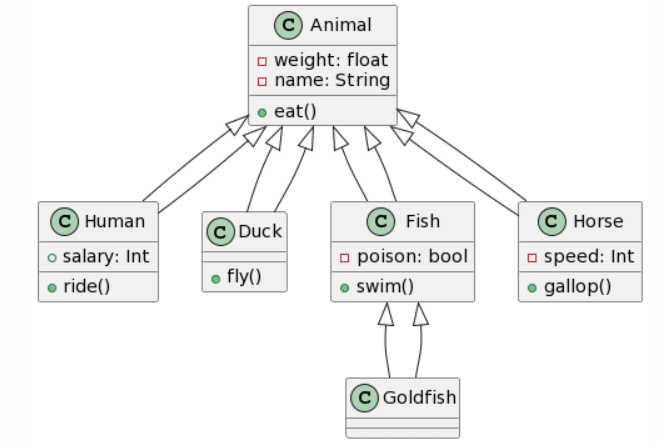 |
De nuevo, ChatGPT4 gana esta ronda repitiendo los mismos errores que antes. Bard crea un resultado casi idéntico, pero de nuevo tiene doble herencia para cada clase, y decidió añadir atributos y métodos adicionales a la clase Animal (lo cual, dependiendo del contexto, podría no ser algo malo). Microsoft Copilot también proporciona un resultado bastante bueno, con la misma estructura que ChatGPT4, pero no respeta el formato dado para los atributos, y parece seguir más bien las convenciones de Java y también ignora la accesibilidad de los atributos. Finalmente, CogVLM de nuevo no tiene relaciones, hace un trabajo bastante aceptable con los atributos, pero ignora aleatoriamente la existencia de la clase Humano.
Finalmente, incrementé una última vez la complejidad, incluyendo cardinalidades y asociaciones con nombre:
| Picture | Expected Outcome |
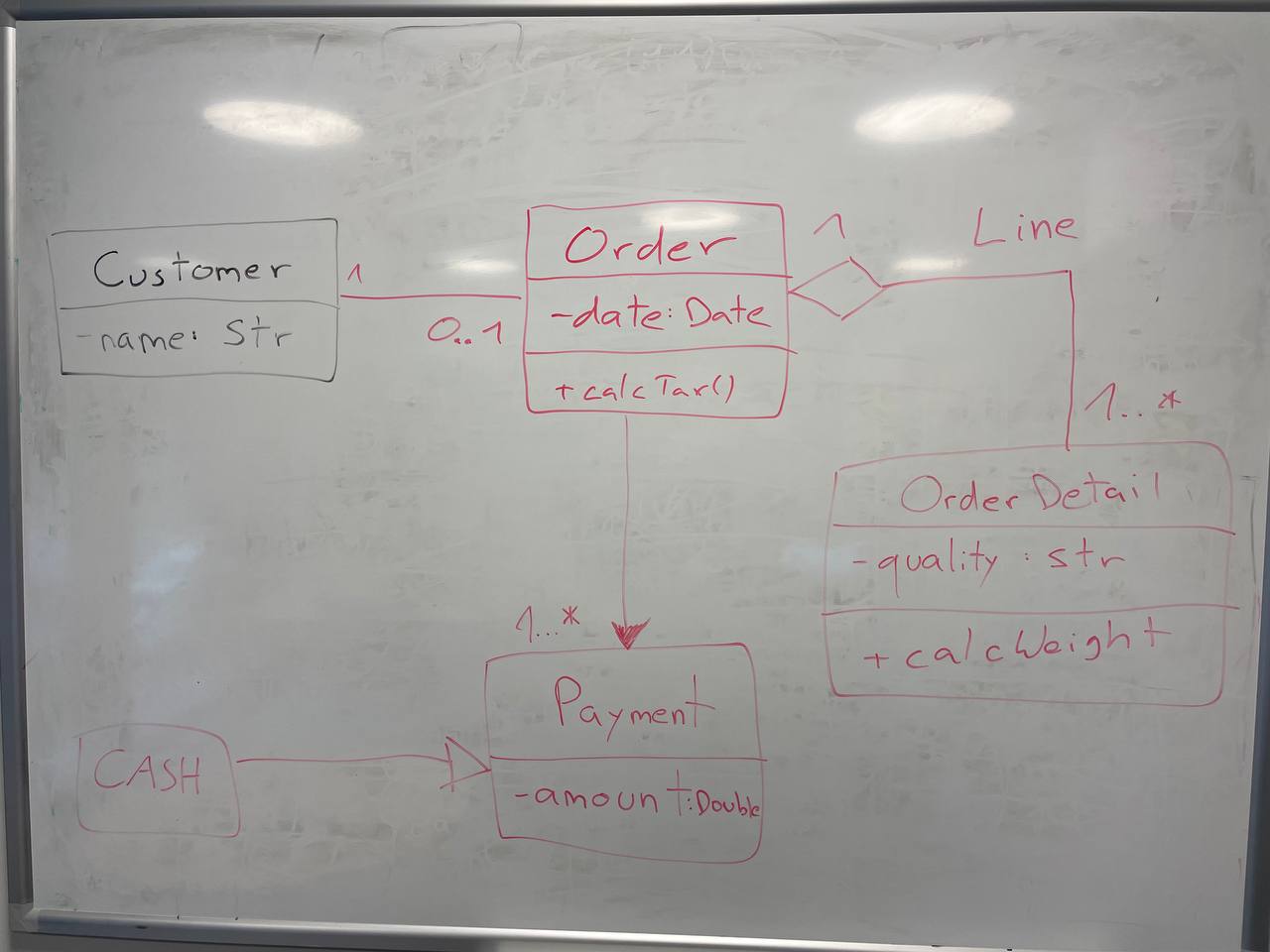 |
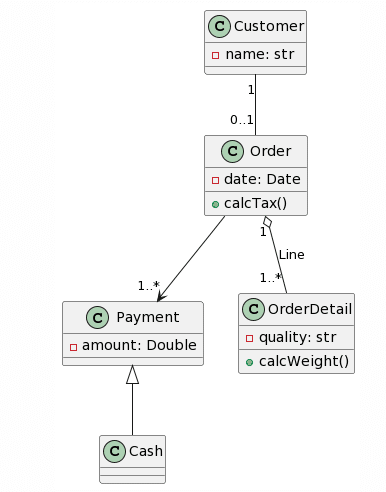 |
Y aquí están los resultados para cada uno de los LLMs:
| Microsoft Copilot: 15 mistakes |
ChatGPT4: 7 mistakes |
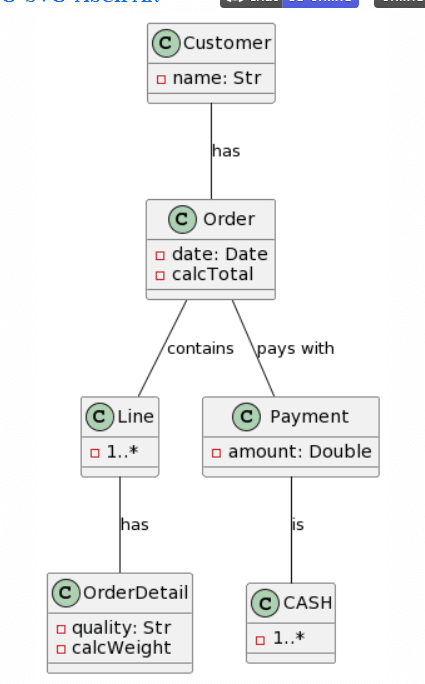 |
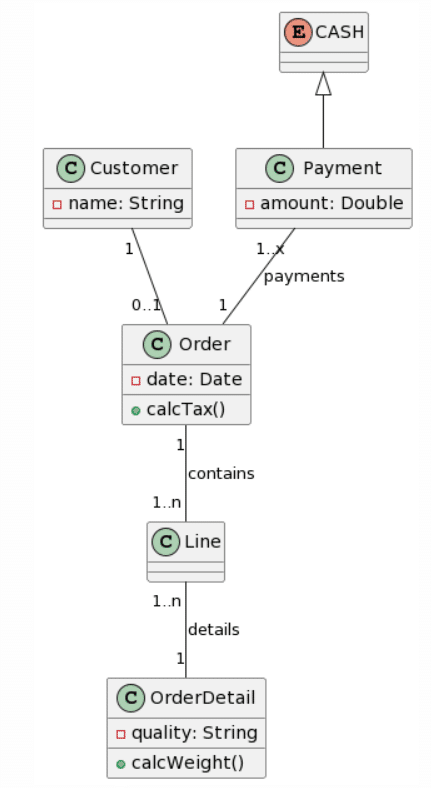 |
| CogVLM: / |
Bard: 22 mistakes |
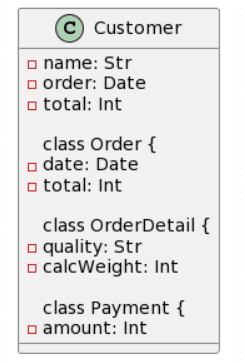 |
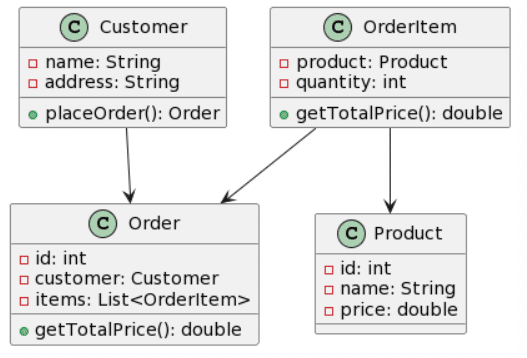 |
Como antes, ChatGPT4 proporciona la mejor generación, aunque no es perfecta, las cardinalidades son bastante correctas, a excepción de que un símbolo de asterisco fue reconocido como una “x”, y la adición de una clase Line en lugar de nombrar la asociación Line. Otro cambio interesante fue la conversión de la clase Cash en una Enumeración. Esta vez, Microsoft Copilot proporcionó una estructura de clases casi correcta, pero falló con las cardinalidades, ya que se agregaron como atributos en algunas clases. Curiosamente, esta vez se mantuvo el formato de los atributos y no se cambió al estilo Java. Sorprendentemente, Bard pareció tener bastantes problemas con este ejemplo, ya que solo acertó 3 clases, “alucinó” la existencia de 1 clase (Producto) y no acertó ninguna asociación. No hay mucho que decir sobre CogVLM.
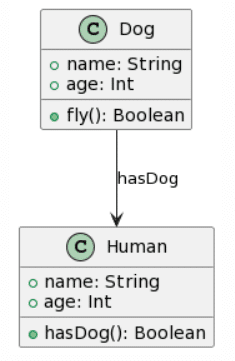
Ahora ya sí para acabar, decidí crear un diagrama de clases sin sentido, en un intento de comprobar cómo reaccionan los LLMs ante una estructura que no tendría sentido en la vida real:
| Picture | Expected Outcome |
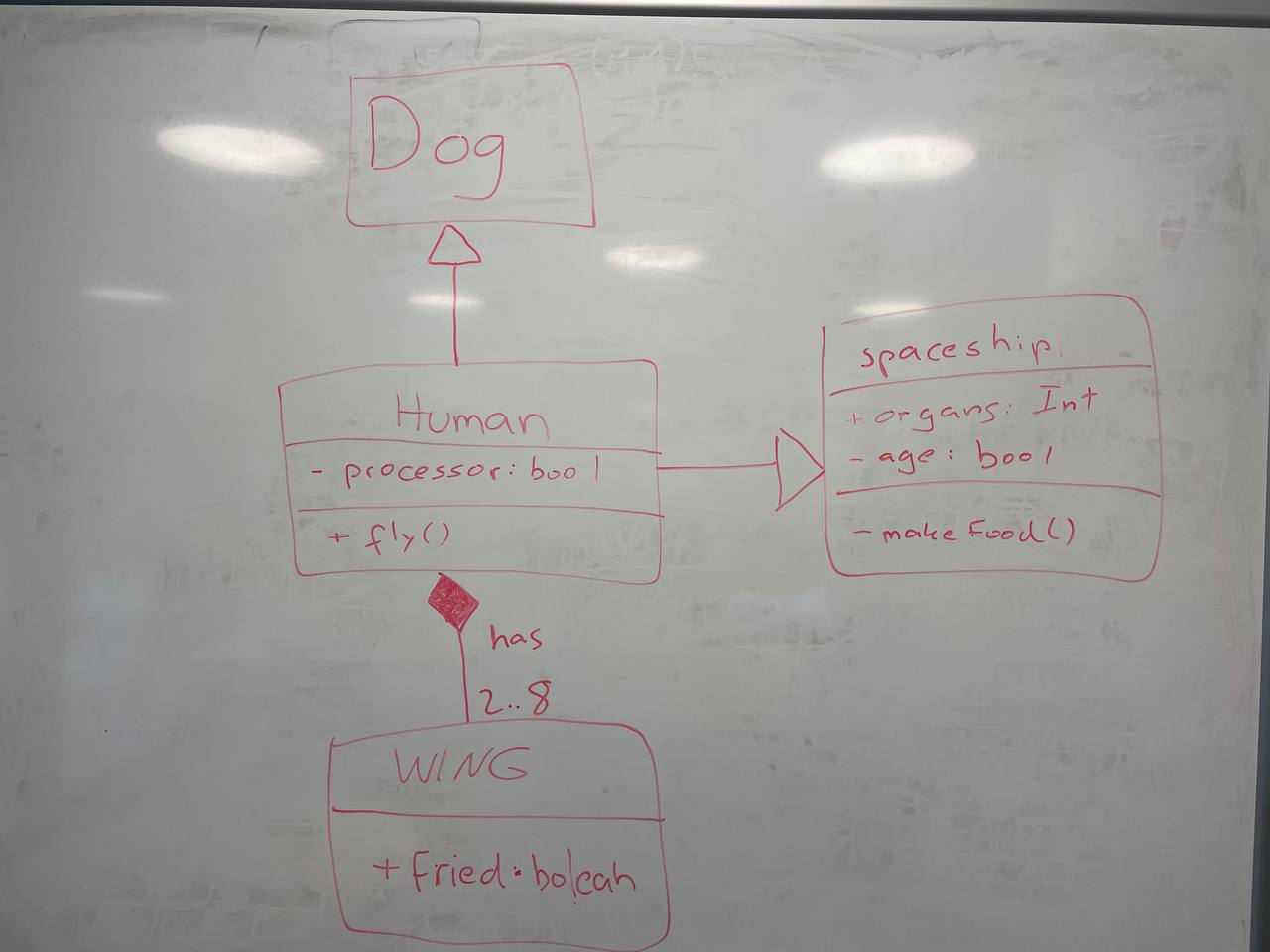 |
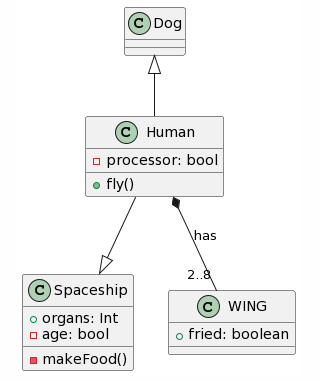 |
Veamos los resultados:
| Microsoft Copilot: 13 mistakes |
ChatGPT4: 5 mistakes |
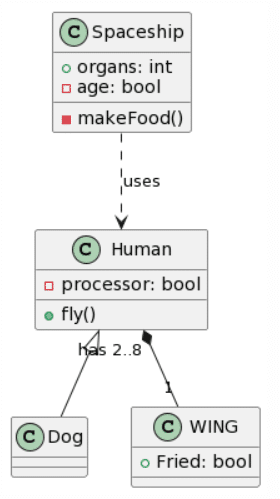
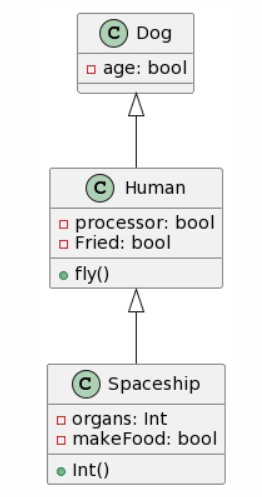 |
 |
| CogVLM: 14 mistakes |
Bard: 17 mistakes |
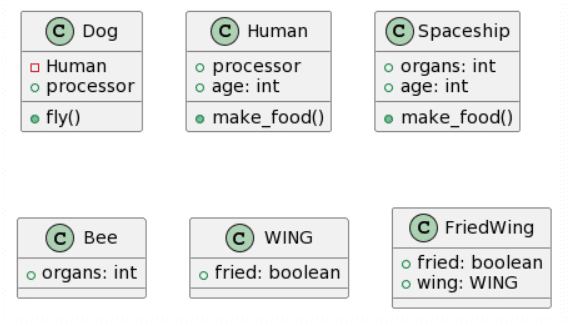 |
 |
Una vez más, ChatGPT4 logra la transformación más completa, aunque con algunos errores importantes como la inversión de las generalizaciones o su transformación en una asociación unidireccional y además coloca las cardinalidades en el extremo equivocado. Microsoft Copilot también logró hacer un trabajo decente, aunque olvidó la clase Wing y añadió atributos inexistentes, en lo positivo logró acertar con una generalización. Bard parece haber eliminado las clases Ala y Nave Espacial y decidió alucinar atributos. CogVLM sigue el mismo patrón habitual de crear algunas de las clases correctas, mientras ignora las relaciones por completo y crea clases aleatorias que podrían encajar en términos de contexto (como FriedWing con Wing).
Discusión
En este breve experimento, me centré únicamente en generar el código PlantUML usando el mismo prompt y juzgando solo el primer resultado proporcionado por el LLM. En general, vimos que ChatGPT4 logró los mejores resultados y actuó de manera más consistente. Sin embargo, usar solo un prompt y evaluar solo el primer resultado podría no ser necesariamente concluyente en términos de resultados. Además, no hay que olvidar que los LLMs no son deterministas y vi como al hacer más pruebas algunos resultados cambiaban ostensiblemente, sobretodo en algunos LLMs. Mientras que ChatGPT4 y CogVLM generalmente proporcionaban resultados de calidad consistente, Microsoft Copilot y Bard parecían proporcionar resultados muy buenos o muy malos dependiendo del intento. Además, a veces, tanto Bard como Microsoft Copilot se negaban a generar algo, ya que ambas herramientas afirmaban no poder manejar la solicitud. Por lo tanto, podría tener sentido realizar una verificación en el backend de si se proporcionó código PlantUML o proporcionar múltiples resultados al usuario y dejar que decida cuál creen que es mejor (aunque implique malgastar más recursos, ya sean recursos computacionales o también monetarios para pagar el uso de los modelos).
Además, el hecho de usar un prompt simple también podría haber afectado los resultados. Como vimos con algunos de los resultados, a veces se agregaban atributos o clases aleatorios que, aunque encajaban en el contexto del ejemplo dado y eran correctos en lógica, no eran deseados por mí. Por lo tanto, crear un prompt más preciso podría haber prevenido tal comportamiento. Un mejor prompt podría haber sido:
“Transforma un diagrama de clases UML dibujado a mano en sintaxis PlantUML. El diagrama dibujado a mano puede incluir relaciones poco convencionales que no tienen sentido en escenarios de la vida real. Ignora el sentido común y concéntrate únicamente en traducir los elementos, clases y relaciones en código PlantUML válido sin añadir descripciones adicionales. Tu objetivo es proporcionar una representación fiel del diagrama dibujado a mano usando sintaxis PlantUML sin añadir descripciones adicionales. Además, cíñete a la notación de clases de UML.”
Un prompt más concreto como éste podría haber proporcionado mejores resultados, especialmente creo que podría haber ayudado a evitar la invención de atributos.
Con respecto a CogVLM, aunque nunca incluyó relaciones en el código PlantUML generado, si se le pedía que describiera el diagrama de clases UML contenido en la imagen, entonces sí que reconocía que había relaciones:
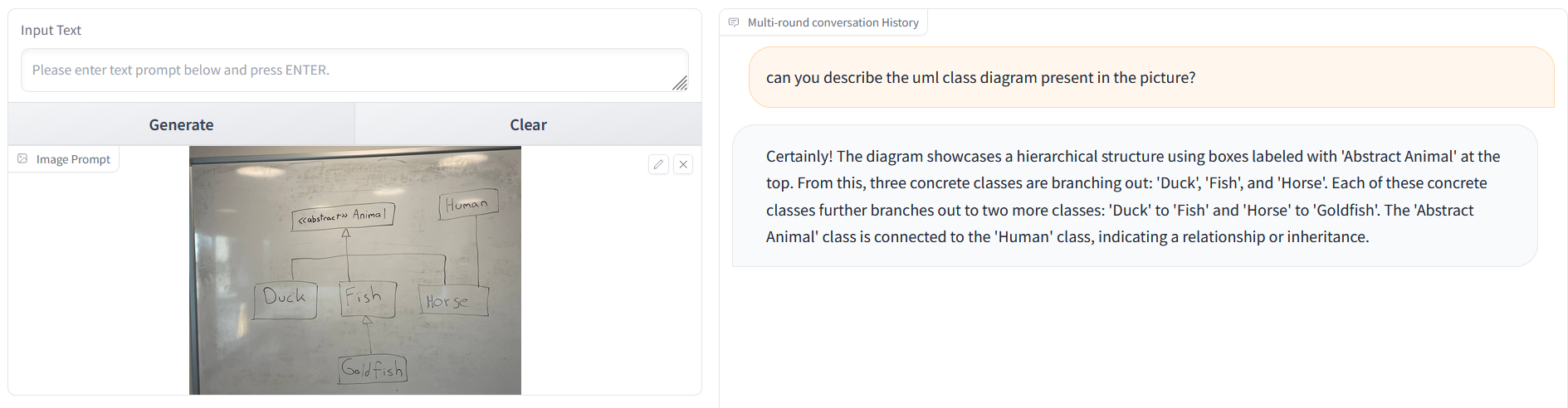
Aunque la descripción proporcionada no es perfecta, parece que la generación de PlantUML también falla en parte debido a que el modelo no es experto en la generación de PlantUML, lo que podría indicar una falta de datos de entrenamiento al respecto. En este punto, si se quisiera seguir utilizando modelos gratuitos, podría ser posible usar la generación de imagen a texto de CogVLM para generar la descripción del diagrama de clases y generar el código PlantUML real utilizando un modelo gratuito de Texto-a-Texto más avanzado.
Si nos fijamos en la naturaleza de los errores, lo más común son fallos en las relaciones ya sea no reconocerlas o reconcerlas de forma errónea. Como los LLM actúan como cajas negras, es difícil razonar los errores. Una posibilidad podría ser que los LLM no reconocen perfectamente el tipo exacto de relación, sino que solo son conscientes de que hay algún tipo de relación. En este punto, podría haber algún porcentaje de confianza sobre el tipo de relación, y si fuera demasiado bajo, el LLM podría decidir hacer sus propias suposiciones. Además, si una relación parece ilógica en la vida real, esto podría disminuir aún más la puntuación de confianza, ya que tal relación podría considerarse como un posible error semántico basado en el conocimiento del LLM.
Conclusiones y Trabajo Futuro
He experimentado con las habilidades de los LLM para convertir imágenes de diagramas de clases UML a código PlantUML. Los resultados iniciales sugieren que, aunque algunos modelos gratuitos crean resultados apropiados, el precio de ChatGPT4 todavía parece compensar en términos de calidad (aunque sorprendentemente, ya que Microsoft Copilot también usa ChatGPT pero tal vez no exactamente la última versión). Además, aunque los modelos gratuitos de Microsoft Copilot y Bard proporcionan buenos resultados, estos no vienen con ningún tipo de API. Por lo tanto, no es posible integrarlos fácilmente en un proceso de desarrollo. De todas formas, mi resumen es que usar los LLMs es útil y ahorra tiempo aunque no evita que tengas que revisarlo a conciencia.
Para trabajos futuros, hay múltiples direcciones interesantes para explorar. En primer lugar, podría ser útil realizar un enfoque más sistemático y completo para comparar los modelos. Esto incluiría realizar más pruebas con el mismo prompt y modelos, por ejemplo, 50 generaciones por prompt y modelo. Además, en lugar de señalar verbalmente algunos de los problemas, necesitaríamos contar más concretamente los errores para proporcionar estadísticas de errores reales. Otra tema a probar sería el prompt óptimo.
O en lugar de solo proporcionar los resultados, se podría especificar que el LLM debería transformar la entrada, pero también actuar como un maestro y proporcionar retroalimentación sobre algunos de los elementos presentes. Para los principiantes en UML, podrían intentar dibujar un diagrama de clases UML que podría tener algunos errores en términos de semántica y no de sintaxis. Un chatbot podría entonces actuar como un maestro y transformar correctamente el diagrama de clases UML, pero señalar algunos aspectos del modelo que podrían necesitar revisión, convirtiéndose así en una herramienta de aprendizaje.
En general, podría ser interesante dejar que ingenieros de software reales o estudiantes de informática utilicen tal herramienta y realizar encuestas para averiguar sobre su utilidad.





{kind=link}
Últimos comentarios