Cada día que pasa nos acercamos más al “viejo” objetivo del End-user development, es decir, permitir que un usuario no técnico sea capaz de tener cierta autonomía en la creación o adaptación de las aplicaciones de las que depende para su trabajo diario. Bajo diferentes nombres (low-code, no-code, no-work,…) todas las grandes empresas siguen esta tendencia.
¿Y qué mejor manera de empoderar un usuario que permitirle hablar con el software en lenguaje natural?. ¿Te imaginas que una persona, sin ningún conocimiento técnico, pueda pedir lo que quiera y que el software que necesita se cree automáticamente para él?. Pues de momento, toca seguir soñando ????. Por mucho que haya algunas demos de generadores de código impresionantes y que herramientas como GitHub Copilot (basado en los modelos OpenAI Codex) sean cada vez más populares, estamos todavía hablando de trozos de código pequeños y parciales. Y a veces incorrectos. Queda mucho por recorrer.
Con una excepción. Hay una área donde sí que pienso que este tipo de herramientas están muy cerca de ser útiles y a la vez utilizables para el gran público: la consulta de bases de datos SQL. Por dos razones:
- El gran interés que tiene este campo. La consulta eficiente de datos es una actividad clave en muchos puestos de trabajo. Aún recuerdo las maravillas que he visto hacer al personal de administración con el Query Builder de Access (para los “jóvenes”: una especie de interfaz gráfica para diseñar consultas) y así no tener que esperar a que les generásemos la consulta SQL equivalente.
- Lo acotado que es este problema. Lo podemos reducir a una transformación que tenga como entrada una cadena de texto que expresa la consulta en lenguaje natural (inglés, español,…) y como salida una cadena de texto equivalente en lenguaje SQL.
No digo que sea fácil, pero sí que es más realista. Hace unos años se había intentado con sistemas de reglas que intentaban reconocer patrones pero con resultados más bien pobres. La llegada de la IA ha revolucionado también este sector. Tenemos ya varios modelos de lenguaje capaces de realizar este tipo de traducción, todos siguiendo la arquitectura Transformers, preentrenados (o “fine-tuned”) con los datasets WikiSQL o Spider.
Los dos incluyen miles de pares de ejemplos de consultas en inglés y su correspondiente traducción a SQL. WikiSQL es más grande pero se limita a ejemplos sobre una única tabla. Spider es más pequeño pero incluye ejemplos de consultas multi-tabla y más complejas.
Los diferentes modelos varían dependiendo de si:
- Aprenden la estructura de la base de datos y son capaces de utilizarla para generar sentencias SQL sintácticamente correctas
- Van más allá de generar el SQL (o incluso no lo generan en absoluto) e intentan dar la solución directamente.
- Interactúan con el usuario para refinar la respuesta y clarificar dudas
El propio repo de WikiSQL mantiene un ranking de las mejores soluciones. Algunos ejemplos relevantes del primer grupo son el Tabular Semantic Parsing de Salesforce o las adaptaciones de t5.
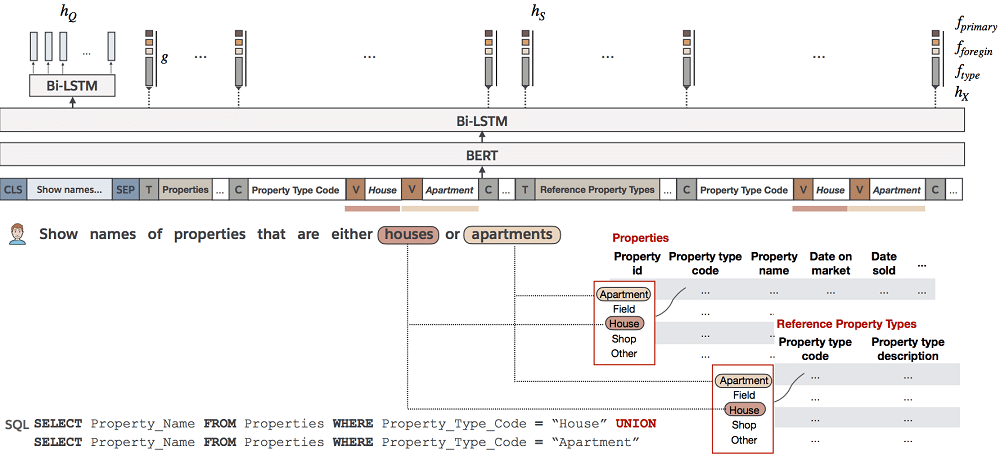
Arquitectura de la herramienta Tabular semantic parsing
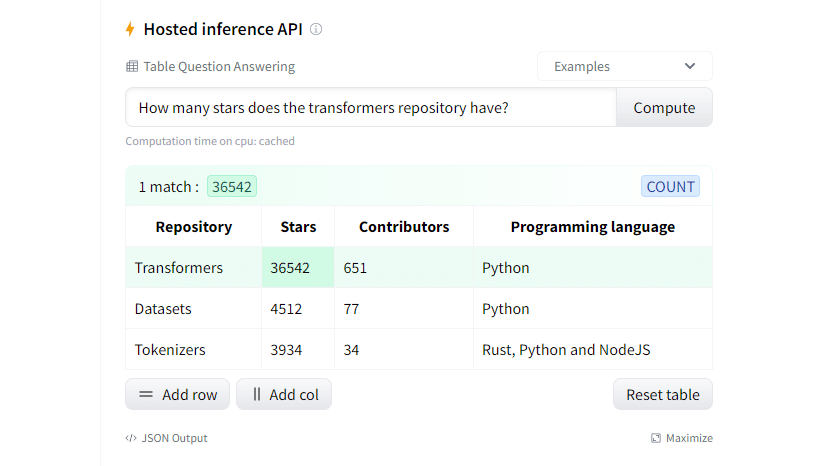
Del segundo grupo, TAPAS es seguramente el más conocido. Y del tercero destacaría este trabajo de Microsoft
Como no podía ser de otra forma, muchos de estos modelos están disponibles en Huggingface con lo que podéis probarlos e incluso integrarlos en vuestros propios proyectos. Salesforce tiene también una demo online, Photon, con la que vale la pena jugar.

Traductor online de lenguaje natural a SQL
El último en aparecer es Zero Shot SQL by Bloom que como su nombre indica tiene dos particularidades:
- Se basa en el modelo Bloom, el modelo multi-lingue más grande, resultado de la colaboración de muchos grupos de investigación alrededor del mundo
- Explora las posibilidades de traducción a SQL de un modelo como Bloom sin un entrenamiento específico.
Insisto, no se trata que los ingenieros software perdamos nuestro trabajo, sino simplemente de qué los usuarios finales puedan hacer su trabajo sin tener que depender de nosotros cada vez que quieran consultar los datos de la base de datos.






{kind=link}
Últimos comentarios