
Cada vez hay más datos disponibles online (el famoso “open data” en inglés). Muchos de ellos están siendo liberados por organismos públicos (ayuntamientos, gobiernos regionales, estatales,…) pero también por empresas privadas. Un ejemplo, el portal de datos europeo tiene más de 400.000 fuentes de datos abiertos registradas.
De hecho parece que cada institución, por pequeña que sea, tiene que crear su propio portal de datos abiertos para mostrar lo bien que cumplen con sus promesas de transparencia con la ciudadanía. Hasta aquí todo bien. El problema es que hay muchos datos abiertos pero nadie que los sepa utilizar. Cada fuente de datos utiliza su propio formato particular (JSON, XML, CVS,…) y, la mayoría de veces, ni se explica cuál es el esquema de esos datos (es decir, que información proporcionan realmente los datos abiertos) sino que simplemente dan los datos crudos (o semiestructurados) y a partir del análisis de los propios datos hay que descubrir su esquema.
Datos en abierto hay muchos pero muy poca es la gente con los conocimientos técnicos para aprovecharse de ellos. Los datos están en abierto pero no se han abierto realmente a la ciudadanía
Podríamos decir que, hoy en día, y pese a los grandes avances realizados, la promesa de poner disponibles todos los datos que los ciudadanos necesitan es eso, una promesa. Sólo expertos con el conocimiento técnico necesario son capaces de acceder, digerir, procesar y acabar haciendo algo útil con esos datos. Estamos muy lejos de un acceso democrático y universal a los datos abiertos.
Si éste es el problema, ¿cuál es la solución?. Desde el grupo de investigación SOM Research Lab, estamos desarrollando una infraestructura que permita a cualquier ciudadano de a pie beneficiarse de las iniciativas open data.
Más concretamente, queremos construir un modelo global unificado del conocimiento disponible en abierto y presentarlo a los ciudadanos de manera que puedan navegar fácilmente y transparentemente por la información que sea de su interés. Técnicamente, las solicitudes de los usuarios se traducirán en una secuencia de accesos a las fuentes de datos necesarios (generalmente, a partir de APIs) para recuperar y combinar los datos y así poder generar el resultado esperado por el usuario. En caso de que se tengan que utilizar diversas fuentes de datos (por ejemplo, debido a un solapamiento de los datos) se tendrán en cuenta factores como la fiabilidad de los datos o incluso los costes monetarios (ya que algunas fuentes pueden ser sólo parcialmente libres) para proporcionar una solución óptima. Con este proyecto se consigue empoderar realmente al ciudadano.
Estamos justo empezando. Está casi todo por hacer (y estaremos encantados de colaborar con quién quiera contribuir también a esta iniciativa). Los pasos a implementar para la consecución del proyecto son:
- APIficación de las fuentes de datos: (Web) APIs son ya el estándar de facto para publicar datos online. La apificación nos permite ofrecer una interfaz vía una API a toda tipo de fuente de datos. Así se homogeneiza el acceso.
- Descubrimiento de los esquemas de datos: La mayoría de datos no vienen con una descripción de su naturaleza que nos ayude a interpretarlos. Por suerte, un análisis sistemático de esos datos nos va a permitir descubrir de forma automática ese esquema que nos falta (para un ejemplo, mirad lo que podemos llegar a hacer con nuestra herramienta JSON Discoverer) así como otras propiedades no funcionales de la fuente (rendimiento, calidad, fiabilidad,…) .
- Composición de esquemas: Se buscarán relaciones entre los esquemas individuales de cara a conseguir un esquema global que explique la totalidad del conocimiento disponible.
- Lenguajes para el “citizen developer”: El acceso a ese esquema global se hará mediante el uso de lenguajes fáciles de usar para usuarios no técnicos. Por ejemplo, se podria usar una interfaz en lenguaje natural (vía chatbots) para que el ciudadano pueda explicar bien qué datos necesita.
- Resolución de consultas: Cada petición sobre el esquema global se va a traducir automáticamente a una secuencia de llamadas a las APIs de cada fuente individual para recuperar y combinar los datos necesarios.
La figura muestra como estos diferentes componentes se van a combinar entre sí.
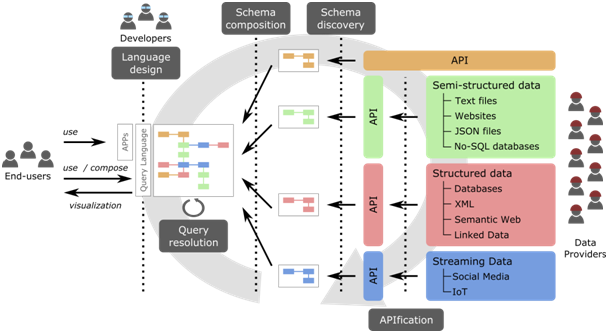
Esquema tecnológica de la propuesta “Open Data for All”
Creemos que el proyecto puede tener un gran impacto a nivel social al proporcionar a cualquier ciudadano acceso (¡ahora sí!) al número creciente de datos abiertos disponible online. Y esperamos que pueda ser también útil tanto a los proveedores de datos (cuya audiencia será ahora mayor) y a desarrolladores (que podrán escribir código más fácilmente gracias a nuestro esquema globla). ¡Veremos si esto es así en unos años!
Imagen de cabecera gracias a Jonathan Gray





{kind=link}
Últimos comentarios