Con el auge de las tecnologías de machine learning (ML), la necesidad de tener más y mejores conjuntos de datos para entrenar estas tecnologías se ha convertido en uno de los retos principales de la industria. Voces relevantes dentro de la comunidad de ML, como Andrew NG, ponen en primer plano la necesidad de centrar futuras investigaciones en los datos usados para entrenar modelos de ML. La idea es sencilla: mejores datos para construir aplicaciones de ML mejores y más potentes.
Pero los datos, más allá de ser el combustible detrás de las aplicaciones de ML, pueden ser también la fuente de problemas éticos y sociales. Recientes estudios como, Khalif et al, muestran como datasets de análisis facial con un número menor de caras de color oscuro reduce la precisión de los elementos de ML para este tipo de caras, provocando una discriminación hacia estas personas. Por otro lado, Bender et al, muestra como un datasets de lenguaje natural captado de hablantes australianos puede impactar en el rendimiento de un modelo de ML orientado a ciudadanos de Estados Unidos.
La necesidad de documentar los datos
Con estos ejemplos vemos la necesidad de ir más allá de simplemente guardar los datos de entrenamiento. ¡Hay que guardar información sobre la procedencia, características y posible impacto social de los datos mismos!.
En respuesta a esta situación, estudios recientes están recopilando estos riesgos y proponiendo la adopción de buenas prácticas para construir datasets (En Knowing Machines están listados los trabajos más relevantes en el campo). En concreto, muchos de estos trabajos proponen guías generales para la documentación de datasets. Estas guías, inspiradas en las problemáticas apuntadas por la comunidad, tienes como objetivo mitigar problemas comunes provenientes de los datasets, y proveer maneras de medir métricas de alto nivel como equidad social, la privacidad o la trazabilidad de los datos.
Sin embargo, estos trabajos están basados en guías generales y texto natural que tiene limitaciones en términos de diseño y uso. Por ejemplo, son difíciles de computar y manipular automáticamente por parte de aplicaciones. Esto limita el beneficio de estas guías ya que no es posible hacer un tratamiento masivo de datasets teniendo en cuenta sus metacaracterísticas. Por ejemplo, no sería fácil buscar automáticamente un dataset que cumpla restricciones de distribución y o procedencia que sean importantes para un problema dado. Esto limita también poder demostrar que un algoritmo que utiliza un modelo entrenado con estos datos cumple con los principios de transparencia y responsabilidad.
Una solución desde el campo de la ingeniería del software
Es en este punto donde viene nuestra propuesta; DescribeML: A tool for describing machine learning datasets. Esta herramienta permite a los creadores de datos describir, en un formato estructurado, los diferentes aspectos de los datos utilizados para entrenar sus modelos de aprendizaje automático. La descripción se realiza en base a un lenguaje específico de dominio (DSL) que hemos propuesto en este informe: A domain-specific language for describing machine learning datasets. La herramienta se presentará próximamente en las conferencias MODELS 2022 y JISBD 2022.
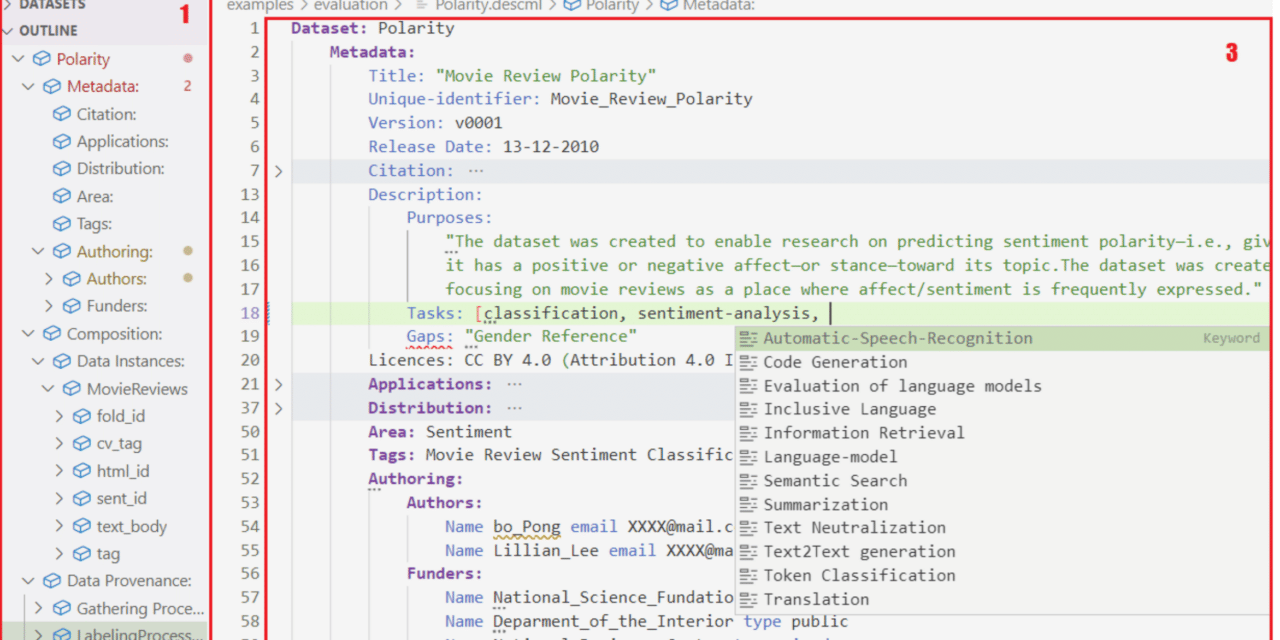
Nuestra herramienta (y el DSL correspondiente) recopila las propuestas recientes de la comunidad sobre documentación de datasets y tiene como objetivo ayudar en la estandarización de estas prácticas. En la siguiente imagen vemos una visión general de la gramática del DSL (expresada como metamodelo con los principales conceptos y relaciones que se pueden usar para anotar datasets). Como vemos, el DSL permite anotar información sobre los usos y autoría de los datos, la composición de estos, su procedencia y los posibles efectos sociales que puedan tener.
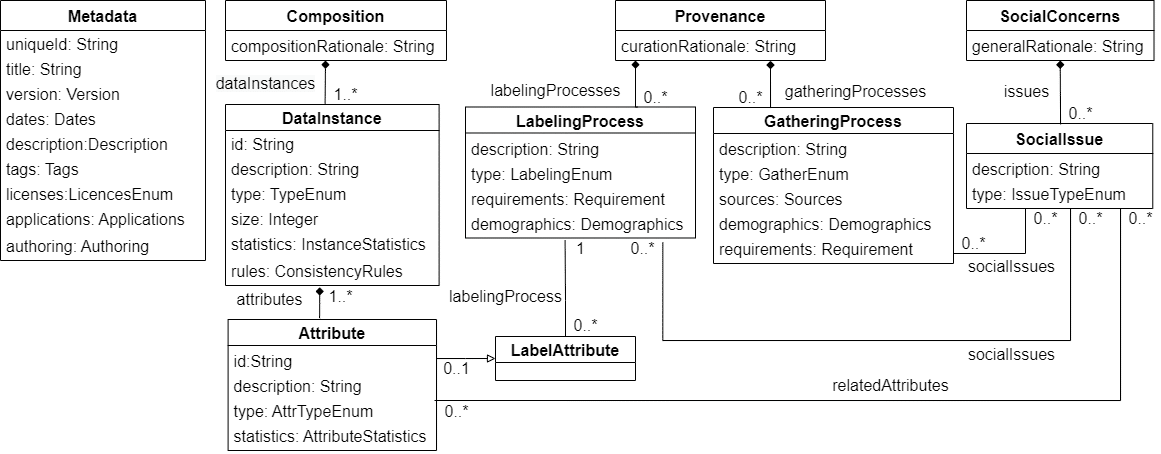
Visión general del metamodelo para describir datasets sobre el que se basa la herramienta
Además, una vez descrito el dataset con nuestra herramienta, se abre la puerta, a un conjunto de escenarios semi-automatizados. Por ejemplo, la comparación de datasets de un mismo dominio, o la búsqueda de los datasets más adecuados para aplicaciones ML concretas, o finalmente, la reaplicabilidad de experimentos (cuando los datos originales no están disponibles). Estos escenarios son un ejemplo de como soluciones desde el campo de la ingeniería del software pueden contribuir avanzar el estado del arte de la IA o de como el campo de la IA necesita del campo ingeniería del software.
Describiendo datos con DescribeML
La herramienta está desarrollada en código abierto como plug-in de Visual Studio Code (VSCode), uno de los entornos de trabajo más populares dentro del campo de ML, y publicada en el marketplace de este. La herramienta ha sido desarrollada usando Languim, un framework de lenguajes basado en TypeScript, y está compuesta por una implementación de la gramática del DSL mencionado y una serie de servicios que extienden las funcionalidades de Visual Studio Code para describir datasets.
La herramienta provee a los creadores de datos con las típicas funcionalidades modernas de lenguajes como resaltado sintáctico, autocompletado, snippets de código y recomendaciones, entre otras. A la vez, la herramienta provee la funcionalidad de cargar los archivos de datos (en .csv) y generar así un fichero de descripción semi-completado para facilitar el uso de la herramienta. Por otro lado, también dispone de funcionalidades de generación como la de generar documentación HTML (con el SEO preparado para que lo detecte Google Dataset Search) a partir de un archivo de descripción válido.
En la imagen siguiente podemos ver una captura de la herramienta sobre VSCode donde la zona marcada con 1, muestra la guía del archivo de descripción que estamos creando, la zona marcada con un 2, muestra los botones de las funcionalidades de carga de datos y generación de documentación HTML, y finalmente, la zona marcada con un 3 muestra el editor de código.
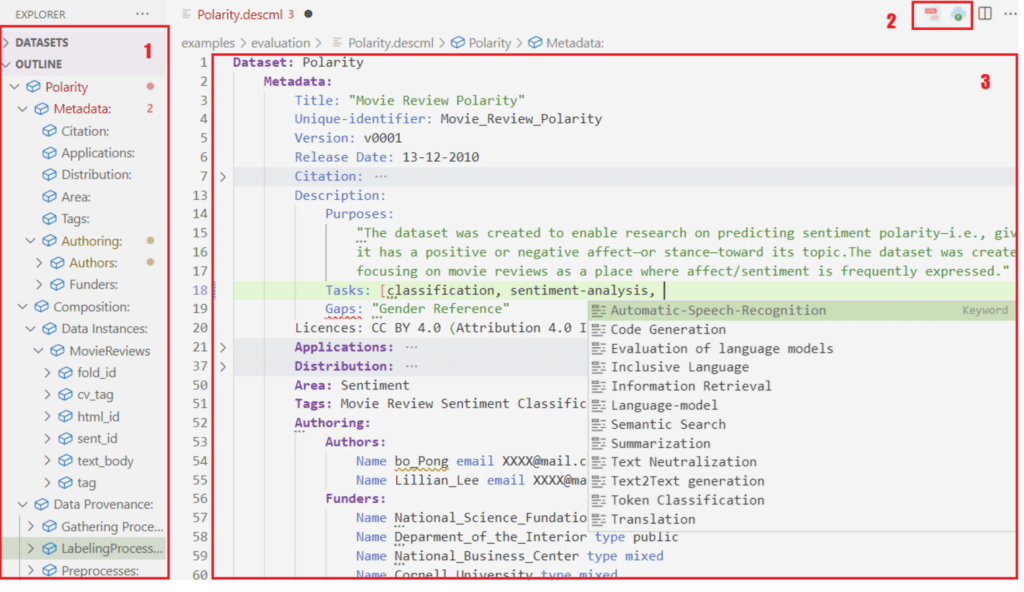
Vista general de la interfaz de usuario de DescribeML
En el siguiente video se hace una breve presentación de la herramienta, mostrando su simple proceso de instalación, el flujo de uso, y dando algunos consejos prácticos para trabajar con ella.
¿Quieres colaborar con nosotros? ¿Quieres saber más sobre nuestro trabajo? No dudes en escribirnos a jginermi@uoc.edu, estaremos encantados de hablar contigo.
Si te ha gustado este trabajo pásate por nuestro repositorio, y danos una Star 😉






{kind=link}
Últimos comentarios